
Music Industry Revenue 2025: Streaming Hits $5.6B at Mid-Year While Vinyl Chases a $1B Milestone
December 10, 2025
How to Archive Music Projects: The 5-Step Backup and Organization Guide for Year-End
December 11, 2025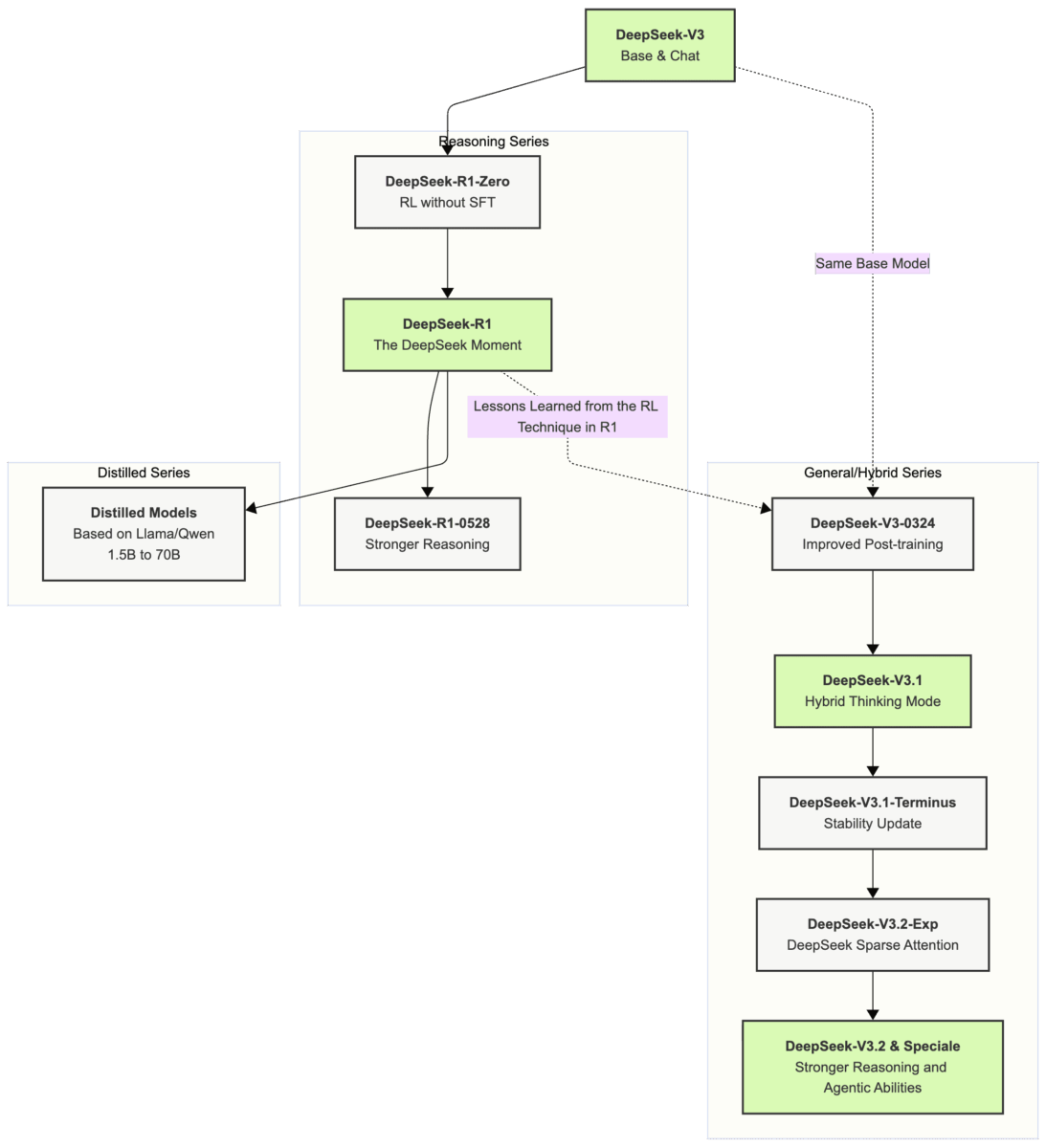
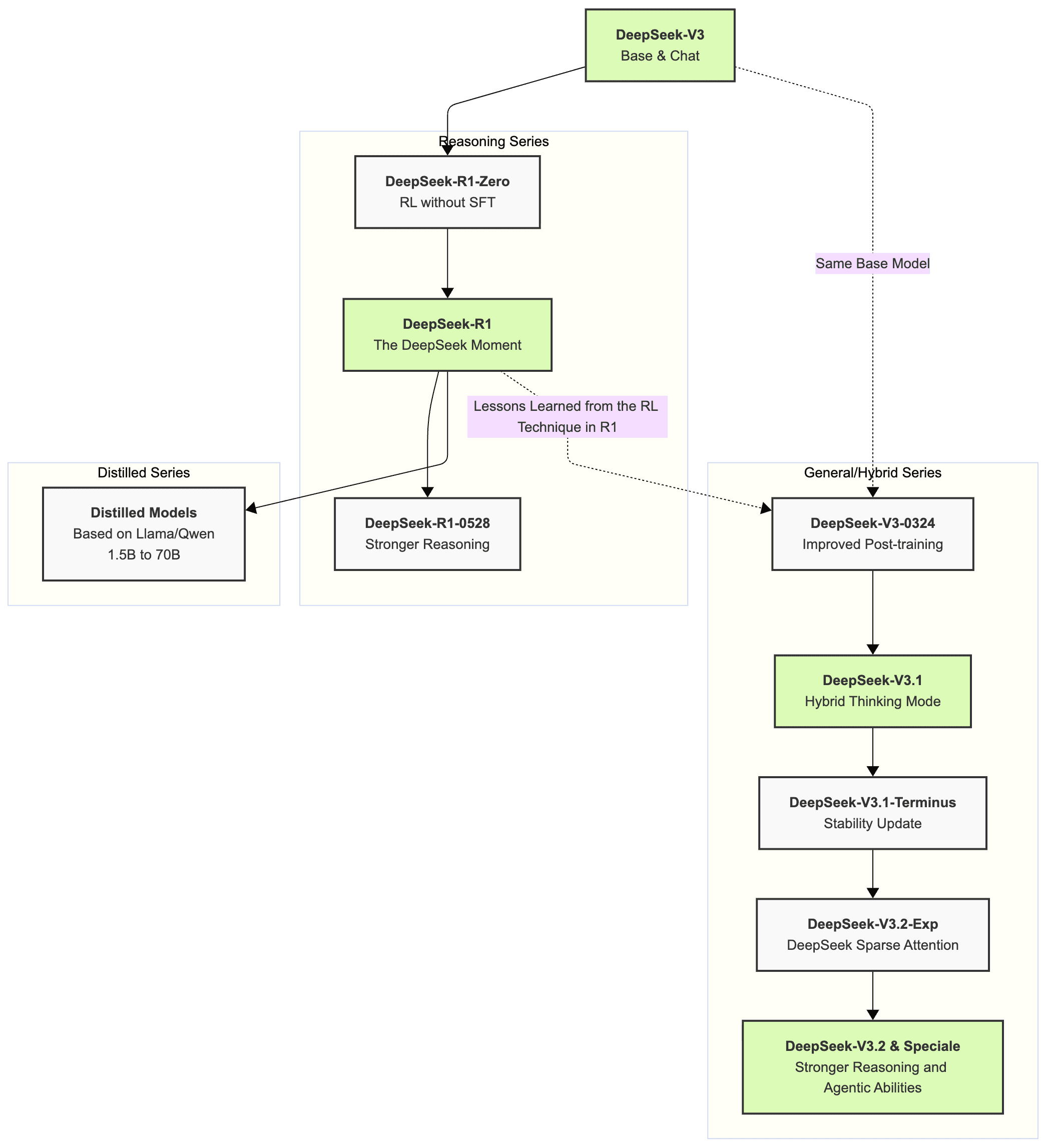
$5.6 million. That’s what it cost to train the AI model that wiped $600 billion off Nvidia’s market cap in a single day, dethroned ChatGPT on the App Store, and forced every major AI company to rethink its strategy. This DeepSeek 2025 year in review traces how a 200-person Chinese lab — funded by a hedge fund, armed with open-source conviction — became the most disruptive force in artificial intelligence this year.
The Origin Story: From Quant Trading to AI Revolution
DeepSeek AI was founded in 2023 by Liang Wenfeng, the founder of High-Flyer, a Chinese quantitative hedge fund that manages billions in assets. With approximately 200 employees — compared to OpenAI’s 3,500 — the company operates at roughly 1/17th the headcount of its biggest rival. Yet throughout 2025, this lean operation consistently punched above its weight in ways that no one in Silicon Valley predicted.
The secret wasn’t some hidden breakthrough in hardware. It was efficiency — relentless, methodical efficiency at every layer of the AI development stack. DeepSeek used 2,048 NVIDIA H800 GPUs and 2.788 million GPU hours to pre-train V3, at a total cost of $5.6 million. For context, OpenAI’s annual burn rate sits around $5 billion. That’s not a typo. DeepSeek achieved comparable performance at roughly 1/1000th the annual expenditure of its largest competitor.
As MIT Technology Review put it, DeepSeek “ripped up the AI playbook” — and the rest of the industry has been scrambling to follow ever since. What makes this even more remarkable is that the efficiency gains weren’t just about clever hardware utilization. They stemmed from fundamentally new training algorithms and architectural decisions that challenged assumptions the Western AI labs had treated as settled science.
The DeepSeek 2025 Year in Review Timeline: A Shockwave Every Quarter
January: R1 Drops, Wall Street Panics
In January 2025, DeepSeek released R1 — a reasoning model that matched OpenAI’s o1 across major benchmarks. The technical innovation that made it possible was GRPO (Group Relative Policy Optimization), a reinforcement learning technique that eliminated the need for a separate reward model. Traditional RLHF approaches required training a reward model alongside the main model, essentially doubling the computational overhead. GRPO removed this entire step, dramatically cutting training costs without sacrificing output quality.
The market reaction was swift and brutal. On January 27th, Nvidia’s stock plummeted by $600 billion in a single trading session — the largest single-stock loss in U.S. market history. The same day, the DeepSeek app hit #1 on Apple’s App Store in the United States, surpassing ChatGPT. Wall Street’s thesis that “whoever buys the most GPUs wins the AI race” suddenly had a $600 billion crack in it. Investors were asking a simple but devastating question: if $5.6 million is enough to match the best, why are we investing tens of billions in GPU infrastructure?
March: V3-0324 Outperforms GPT-4.5
DeepSeek-V3-0324 integrated reinforcement learning techniques from R1 into the base model architecture, pushing reasoning capabilities significantly forward. Multiple benchmarks showed it outperforming GPT-4.5 — a model trained with vastly more resources. The improvement was particularly striking in coding and mathematical reasoning tasks, demonstrating that the systematic reasoning abilities trained in R1 could successfully transfer to general-purpose models.
The narrative that open-source AI couldn’t keep pace with closed models wasn’t just challenged; it was being systematically dismantled. Every quarter, DeepSeek was releasing models that matched or exceeded closed-source competitors, while simultaneously making everything available for the global research community to build upon. This flywheel effect — open-source release leading to community contributions leading to faster iteration — was proving to be a genuine competitive advantage.
May: R1-0528 Cuts Hallucinations by 45-50%
The May update to R1 doubled reasoning tokens to 23K while simultaneously reducing hallucinations by 45-50%. This wasn’t just about making the model smarter — it was about making it trustworthy. Hallucination has been the Achilles’ heel of large language models since GPT-3, and DeepSeek attacked it head-on with measurable results.
For enterprises evaluating AI adoption, this hallucination reduction rate mattered more than any benchmark score. A model that’s brilliant but unreliable is worse than useless in production environments — it’s actively dangerous. By cutting hallucination rates nearly in half, DeepSeek moved the conversation from “can AI do this?” to “can we trust AI to do this?” And increasingly, the answer was yes.
August: V3.1 Showcases MoE at Scale
DeepSeek-V3.1 arrived in August with 671 billion parameters — but only 37 billion activated at any given time, thanks to the Mixture of Experts (MoE) architecture. It featured hybrid thinking modes and a 128K context window, along with the newly introduced DeepSeek Sparse Attention mechanism for dramatically improved long-context efficiency.
The philosophy was pure DeepSeek: build something massive, but run it lean. MoE architecture wasn’t new, but nobody had executed it this effectively at this scale for public use. The practical implication was enormous — developers could access the knowledge breadth of a 671B-parameter model at the inference cost of a much smaller one. For anyone working with long documents, complex codebases, or multi-step reasoning tasks, the difference was immediately tangible.
December: V3.2 Goes Head-to-Head with Google and OpenAI
Just 10 days ago, on December 1st, DeepSeek released V3.2 and V3.2-Speciale. Bloomberg reported these models as direct rivals to Google and OpenAI’s latest offerings. What started in January as a “promising challenger” narrative has evolved into something far more significant: DeepSeek is now a top-tier competitor, full stop.
The pace of iteration itself is remarkable. Six major model releases in 12 months, each one pushing boundaries without compromising quality. For a 200-person team, this velocity of output would be impressive even without the benchmark results. Combined with the performance numbers, it’s unprecedented.
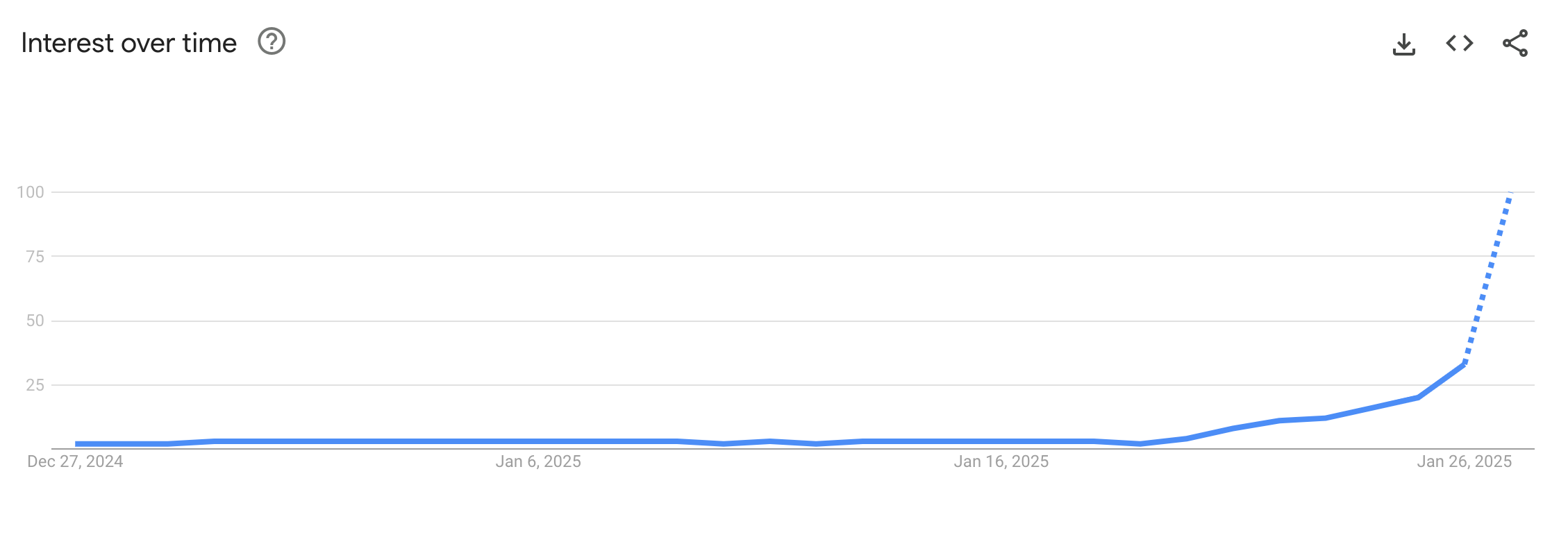
How the Industry Responded: Giants Forced to Adapt
DeepSeek’s impact in 2025 wasn’t limited to impressive benchmarks. It fundamentally altered the competitive dynamics of the entire AI industry. Here’s how the major players responded:
- Google fast-tracked the launch of Gemini 2.0 Flash specifically to counter DeepSeek’s momentum. Internal timelines were reportedly accelerated by months.
- OpenAI released a free o3-mini model — a move widely interpreted as a direct response to DeepSeek’s pricing pressure. Sam Altman publicly called R1 “impressive,” an unusually generous acknowledgment of a competitor.
- Nvidia faced fundamental questions about its GPU demand thesis after the $600B single-day wipeout. If AI training can be done with fewer GPUs, the entire investment thesis for the AI hardware boom needs recalibration.
- The benchmark cost revolution: achieving equivalent AI benchmark scores dropped from $4,500 per task to just $11.64 per task over the course of 2025 — a staggering 387x improvement in cost efficiency.
The Brookings Institution argued that DeepSeek proved competition beats Big Tech monopolies — that open-source disruption of the closed-model paradigm isn’t just idealistic, it’s empirically superior. Info-Tech Research Group’s industry assessment highlighted that DeepSeek’s API pricing at $0.55/$2.19 per million tokens (versus OpenAI o1’s $15/$60) forced the entire market to recalibrate its pricing expectations.
4 Key Technical Innovations That Powered DeepSeek’s Rise
DeepSeek’s story isn’t just about being cheap. The technical innovations behind the cost efficiency are what make the company genuinely significant. Here are the four breakthroughs that defined their 2025:
- GRPO (Group Relative Policy Optimization): Eliminated the need for a separate reward model in reinforcement learning, cutting training pipeline complexity and cost simultaneously. This technique has already been adopted by multiple other research groups.
- MoE (Mixture of Experts) Architecture: 671B total parameters with only 37B activated per query, delivering large-model knowledge at small-model inference costs. DeepSeek’s implementation at scale proved MoE is production-ready, not just a research curiosity.
- DeepSeek Sparse Attention: A custom attention mechanism that dramatically improves computational efficiency for long-context processing (128K tokens), making it practical to work with extensive documents and codebases.
- Full Open Source: Code, weights, and technical papers — all released publicly. This strategy created a global community of contributors while simultaneously pressuring closed-model competitors to lower prices and release free tiers.
4 Lessons from the DeepSeek 2025 Year in Review
1. Money isn’t everything. $5.6 million vs. $5 billion annual burn. DeepSeek proved that resource constraints breed creativity. Their GRPO technique, MoE architecture optimization, and sparse attention mechanisms were born from necessity — and they outperformed solutions built with virtually unlimited budgets. This lesson extends far beyond AI: in technology, constraints often produce better solutions than abundance.
2. Open source is a competitive moat. DeepSeek open-sourced everything: code, model weights, and technical papers. This attracted global research talent, accelerated iteration cycles, and put relentless pricing pressure on closed-model competitors. OpenAI releasing free models and Google expediting launches are direct consequences of this strategy. The flywheel of open contribution is proving to be more powerful than the walled garden approach.
3. MoE architecture is the future. The 671B parameters / 37B activated approach solved the age-old performance-versus-efficiency tradeoff. Expect this to become the default architecture for frontier models going forward. It’s not just DeepSeek — the entire industry is pivoting to MoE because DeepSeek proved it works at scale, in production, with real users.
4. The API pricing race has only just begun. At 1/30th of OpenAI’s pricing, DeepSeek didn’t just compete on quality — it demolished the pricing structure that Big Tech relied on for margins. This pressure will intensify through 2026, benefiting every developer and company building on top of AI APIs. The era of $60-per-million-token output pricing is over.
Looking Ahead: Where Does DeepSeek Go in 2026?
As 2025 draws to a close, DeepSeek’s trajectory is unmistakable. V3.2-Speciale’s performance signals that 2026 will see this lab competing head-to-head with OpenAI, Google, and Anthropic at the very frontier of AI capabilities. Their mathematical prowess is particularly noteworthy — DeepSeekMath-V2 scored 118/120 on the Putnam Competition, well above the human high score of 90. This suggests superhuman performance in specialized domains isn’t a future promise; it’s already here.
2025 will be remembered as the year the equation “more capital = better AI” was definitively broken. DeepSeek stood at the center of that rupture. The question now isn’t whether a 200-person lab can compete with trillion-dollar corporations — DeepSeek already answered that. The question is what new landscape this disruption creates in 2026, and how every AI company, developer, and enterprise will need to adapt to a world where efficiency trumps spending.
Interested in AI strategy consulting or building automated systems? Let’s talk.
Get weekly AI, music, and tech trends delivered to your inbox.



{kind=link}
{kind=link}
{kind=link}