
Best USB-C Hubs 2025: 7 Multi-Port Adapters Every Laptop User Needs in May
May 27, 2025
5 Mixing Mistakes Beginners Make: Common EQ and Compression Errors
May 28, 2025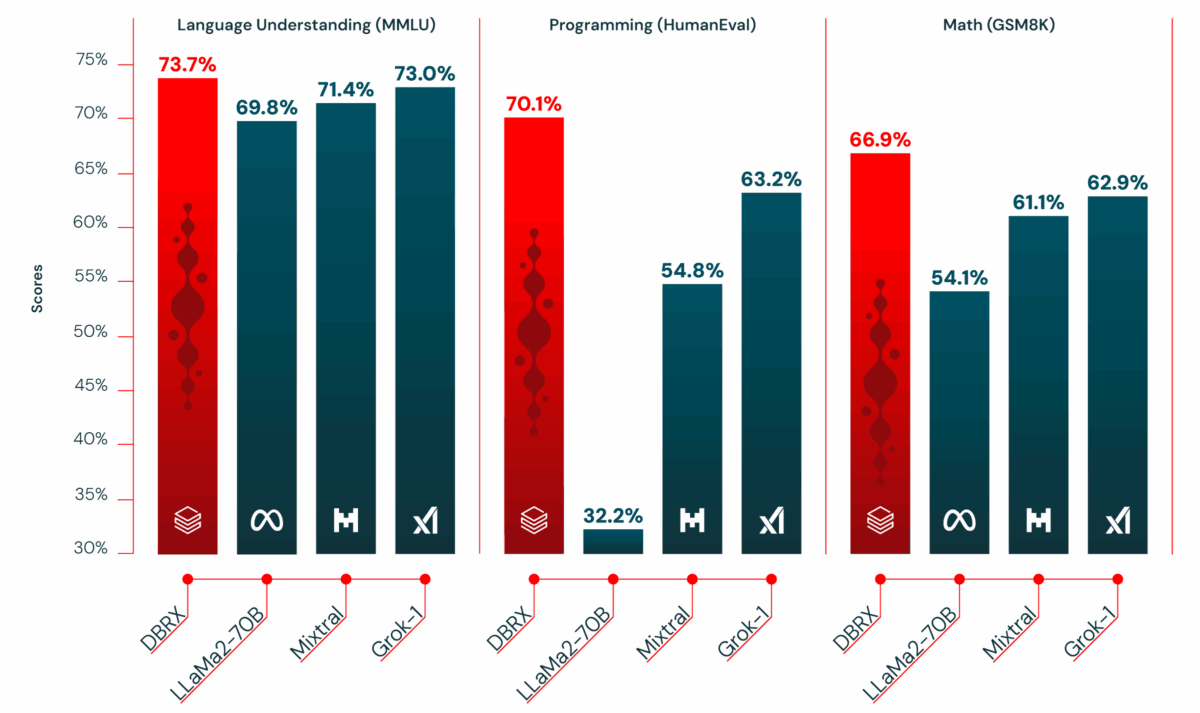
A 132B parameter model activates just 36B parameters at inference — and still outperforms models nearly twice its active size. That is not a theoretical claim. Databricks DBRX has been proving it in production for over a year now, and the implications for enterprise AI strategy are far bigger than most decision-makers realize.
What Makes Databricks DBRX Different: Fine-Grained MoE Architecture
The core innovation behind Databricks DBRX is its fine-grained Mixture of Experts (MoE) architecture. The model contains 132 billion total parameters organized into 16 expert networks. During inference, a sophisticated routing mechanism selects exactly 4 of these 16 experts for each token, meaning only 36 billion parameters are active at any given time. This is not just a clever engineering trick — it fundamentally changes the economics of large language model deployment in enterprise environments.
To understand why this matters, compare it directly to a dense model like Llama 2 70B. Every single inference pass through Llama 2 activates all 70 billion parameters without exception. Databricks DBRX activates roughly half that number while storing nearly twice the total knowledge across its expert networks. The result is a model that effectively knows more, responds with higher quality, and costs significantly less to run per token in production.
According to Databricks’ official announcement, the fine-grained approach — selecting 4 from 16 experts — creates 65 times more expert combinations than Mixtral’s 8-choose-2 architecture. This dramatically increased granularity allows the model to route each token through the most relevant knowledge pathways available, resulting in measurably better output quality across diverse tasks from code generation to complex reasoning.
The architectural innovations extend well beyond the MoE layer. DBRX incorporates Rotary Position Embeddings (RoPE) for superior positional understanding across long sequences, Gated Linear Units (GLU) for improved information flow between layers, and Grouped Query Attention (GQA) for efficient memory usage during long-context processing. The model supports a generous 32K token context window and uses the GPT-4 tokenizer (tiktoken), making it immediately compatible with existing toolchains and prompting strategies that teams have already built around OpenAI’s ecosystem.
” alt=”Databricks DBRX benchmark comparison chart showing performance across multiple tests”/>
Databricks DBRX Benchmarks: The Numbers That Turned Heads
Benchmark results tell a compelling and consistent story about what fine-grained MoE can achieve. On MMLU (Massive Multitask Language Understanding), Databricks DBRX scored 73.7%, clearly surpassing GPT-3.5’s 70.0% and beating Llama 2 70B by an even wider margin. On HumanEval, which rigorously measures code generation ability, DBRX achieved an impressive 70.1% compared to GPT-3.5’s 48.1% — a gap of over 22 percentage points that signals genuine superiority in programming tasks.
The HellaSwag benchmark is where things get particularly interesting for the enterprise AI community. Databricks DBRX scored 89.0%, which not only handily beats GPT-3.5’s 85.5% but actually exceeds GPT-4’s 84.7% on this specific commonsense reasoning test. Let that sink in for a moment: an open-source model with only 36B active parameters outperforming GPT-4 on any established benchmark was nearly unthinkable just two years ago. It signals a fundamental shift in what open models can achieve.
On GSM8k, a rigorous math reasoning benchmark, DBRX posted a solid 66.9%. Taken together, these numbers across multiple evaluation dimensions demonstrate a clear principle: 36B active parameters, when intelligently routed through a fine-grained MoE architecture and trained on 12 trillion tokens of diverse text and code data, can consistently match or exceed dense models with 70B or more parameters. The training data volume deserves special emphasis here — Llama 2 was trained on 2 trillion tokens, meaning DBRX consumed six times more training data, giving each expert network deeper and broader knowledge to draw from.
Inference Speed and Training Efficiency: 2x Faster Than Llama 2 70B
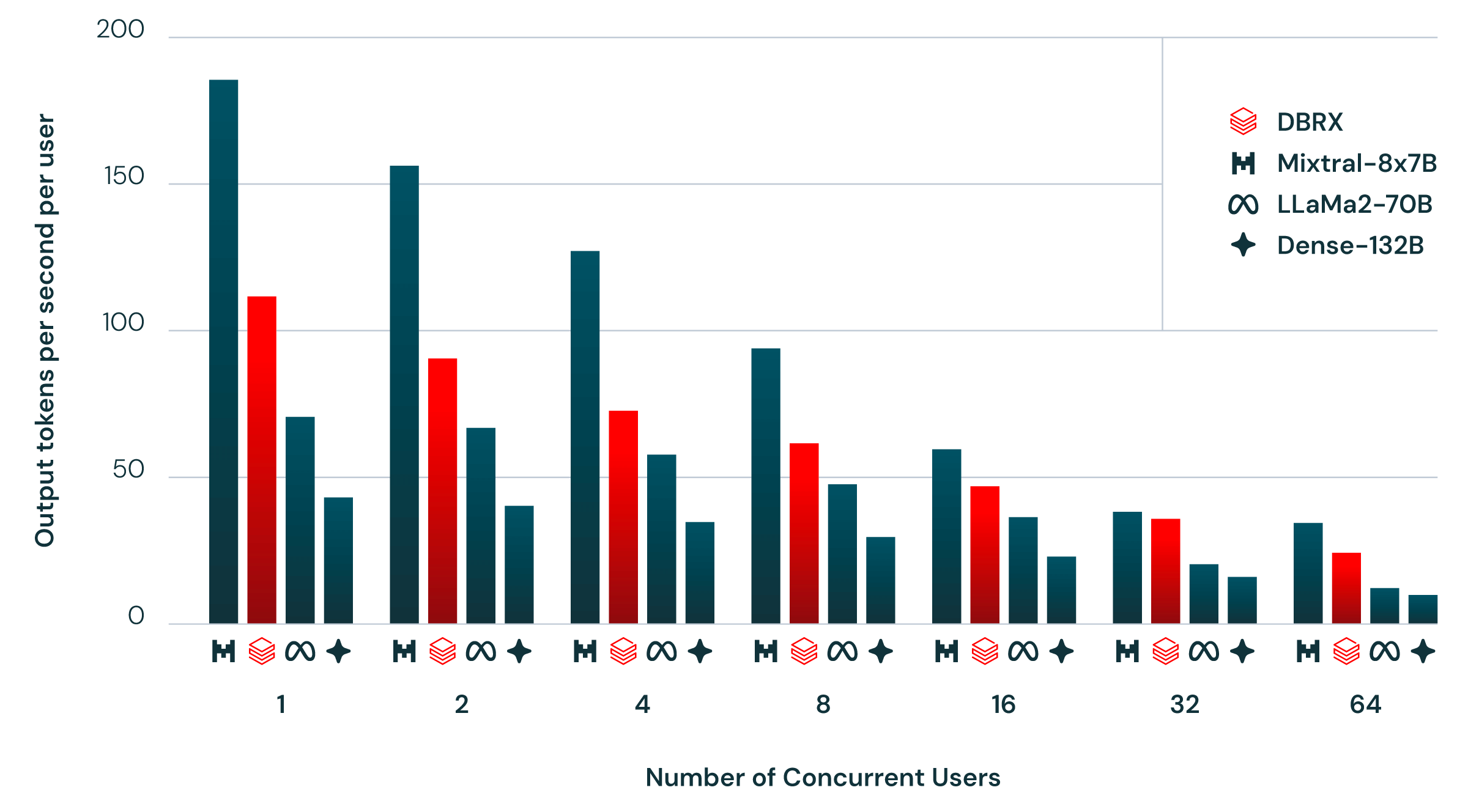
In real-world enterprise deployments, latency and throughput matter every bit as much as raw accuracy scores. A model that gives perfect answers but takes too long to respond is useless for customer-facing applications. Databricks DBRX delivers up to 150 tokens per second in inference throughput, approximately 2x faster than Llama 2 70B. With fewer active parameters doing the computational work on each forward pass, inference completes significantly faster — and that speed advantage compounds dramatically at scale when you are serving thousands of concurrent users.
NVIDIA’s technical blog provides detailed analysis of how DBRX can be further optimized with TensorRT-LLM for even better latency and throughput characteristics in production serving environments. The model is also fully supported by NVIDIA NIM microservices for simplified containerized deployment, with claimed developer accessibility improvements of 10-100x compared to traditional deployment workflows. DBRX demonstrates particular strength in programming and coding tasks, text completion, few-turn conversational interactions, and retrieval-augmented generation (RAG) workloads — precisely the use cases that enterprise teams care most about.
Training efficiency tells an equally compelling story for organizations considering building custom models. MoE architectures are roughly 2x more training-efficient than modern dense models at equivalent performance levels, meaning you need half the compute budget to reach the same quality bar. Compared to Databricks’ previous flagship model MPT, DBRX achieved 4x greater training efficiency — a generational leap that reflects both architectural improvements and better data curation practices. For enterprise AI teams with limited GPU budgets, this efficiency gap can mean the difference between a viable custom model project and one that never gets off the ground.
The Open-Source Strategy: Reshaping Enterprise AI Adoption
Perhaps the most strategically significant aspect of Databricks DBRX is its release as a fully open model. Both DBRX Base and DBRX Instruct variants are publicly available on GitHub and Hugging Face under the Databricks Open Model License. For enterprises that have been cautiously watching the closed-versus-open AI debate from the sidelines, DBRX presented a genuinely credible open-source option that did not require sacrificing output quality or benchmark performance.
” alt=”Databricks DBRX API interface screenshot showing enterprise deployment options”/>
The practical implications for regulated industries are especially significant. Companies operating under strict data governance requirements — think healthcare systems handling patient records, financial institutions processing transaction data, and defense contractors managing classified information — can now deploy a model that beats GPT-3.5 on major benchmarks entirely within their own infrastructure. No sensitive data leaves the corporate firewall. No dependency on third-party API availability or pricing changes. Full organizational control over fine-tuning, evaluation pipelines, and serving infrastructure.
Databricks wisely offers DBRX through their Foundation Model APIs with two distinct pricing models: pay-per-token for variable and experimental workloads, and provisioned throughput for predictable, high-volume production use cases. This dual approach creates a practical adoption path where organizations can start with managed APIs to validate their use cases, then migrate to self-hosted deployments as their needs mature and scale — reducing both technical and financial risk during the transition to enterprise AI.
The 320GB Reality Check: Practical Deployment Considerations
Self-hosting Databricks DBRX comes with a significant hardware requirement: a minimum of 320GB of GPU memory. In practical terms, that translates to at least four NVIDIA A100 80GB GPUs or equivalent hardware, which represents a non-trivial infrastructure investment. The MoE architecture requires all 132B parameters to be loaded into memory even though only 36B are active during any given inference pass — the routing mechanism needs instantaneous access to all 16 expert networks in order to select the optimal 4 for each token.
However, this number needs proper context to evaluate fairly. A 70B dense model delivering comparable benchmark performance requires similar total GPU memory allocation while producing inference results at half the speed. When you calculate throughput per dollar over months of continuous 24/7 production operation, DBRX’s total cost of ownership frequently works out lower than its dense competitors. The upfront hardware investment is comparable, but you extract substantially more useful work per GPU-hour — a difference that accumulates rapidly in high-volume enterprise deployments.
Developed by the Mosaic AI team within Databricks and trained on NVIDIA DGX Cloud infrastructure, DBRX benefits from thoroughly documented cloud deployment paths across all major cloud providers. For organizations that are not yet ready to invest in dedicated on-premises GPU infrastructure, Databricks’ managed serving options provide an immediate, low-friction path to production deployment without the operational overhead of maintaining GPU clusters, managing model updates, or handling scaling challenges in-house.
One Year Later: What Databricks DBRX Proved and What Comes Next
As of May 2025, Databricks DBRX has been available for just over a year, and its impact on the enterprise AI landscape is now clear enough to assess with confidence. The single most important thing this model proved is that Mixture of Experts is not merely a research curiosity or academic exercise — it is a practical, production-ready architecture for serious enterprise AI applications. DBRX demonstrated conclusively that you can achieve superior performance with fewer active parameters if your routing mechanism is sophisticated enough and your training data is sufficiently comprehensive.
DBRX also validated a crucial strategic thesis that has since reshaped the industry: the future of LLM competition is fundamentally not about who can train the largest dense model with the most parameters, but about who can extract the greatest value per unit of compute. This efficiency-first philosophy has influenced virtually every major model release in the open-source ecosystem over the past year. The fine-grained MoE approach that DBRX pioneered and validated at enterprise scale has rapidly become an architectural standard that newer models build upon.
Challenges undeniably remain. The 320GB memory footprint continues to keep self-hosting out of reach for smaller organizations and startups with limited GPU budgets. Subsequent open models like Llama 3 and Mistral Large have further raised the competitive performance bar, creating a rapidly evolving landscape where last year’s breakthrough quickly becomes this year’s baseline. But DBRX’s foundational contribution to proving MoE viability at enterprise production scale will continue to shape how models are designed, trained, and deployed for years to come.
For any organization currently evaluating its enterprise AI strategy, the Databricks DBRX story offers one unmistakable lesson: the biggest model is not always the best model for your use case. Architecture efficiency, deployment flexibility, data governance compatibility, and total cost of ownership matter far more than raw parameter counts on a spec sheet. Databricks DBRX proved that principle convincingly — with 132 billion parameters and the architectural discipline to activate only the 36 billion that matter most for each task.
Looking to navigate enterprise AI model selection or build MoE-based systems? Let’s find the right solution for your needs.
Get weekly AI, music, and tech trends delivered to your inbox.



{kind=link}
{kind=link}
{kind=link}