
Framework Laptop 13 AMD Review: Modular Repairability Meets Ryzen AI Power in 2025
August 29, 2025
iPhone 17 Pro Review: Camera Bar Design, A19 Pro Vapor Chamber, and 8x Zoom — The Biggest iPhone Redesign Since X
September 1, 2025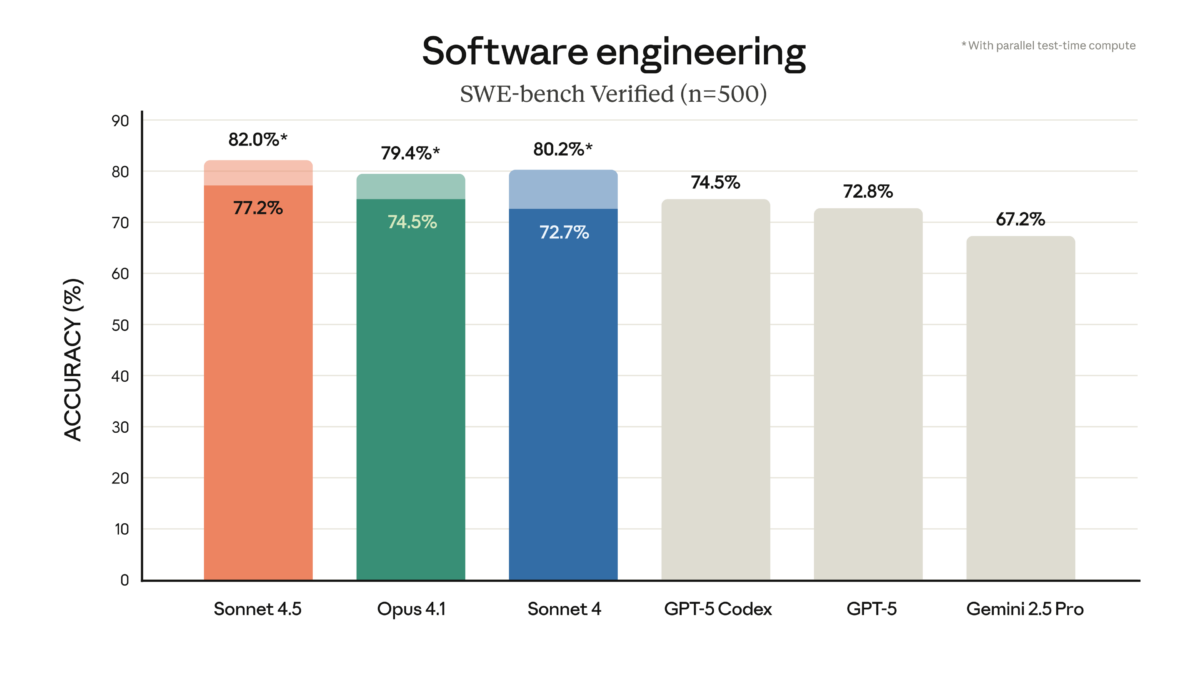
Anthropic just mass-deployed its most dangerous weapon in the AI coding wars — and it costs exactly the same as the model it replaces. Claude Sonnet 4.5 dropped on September 29, 2025, scoring 77.2% on SWE-bench Verified and running autonomously for over 30 hours straight. If you’ve been sitting on the fence between Claude and GPT-5 for your development workflow, this release might just push you off it.
Claude Sonnet 4.5 Benchmarks: The Numbers That Matter
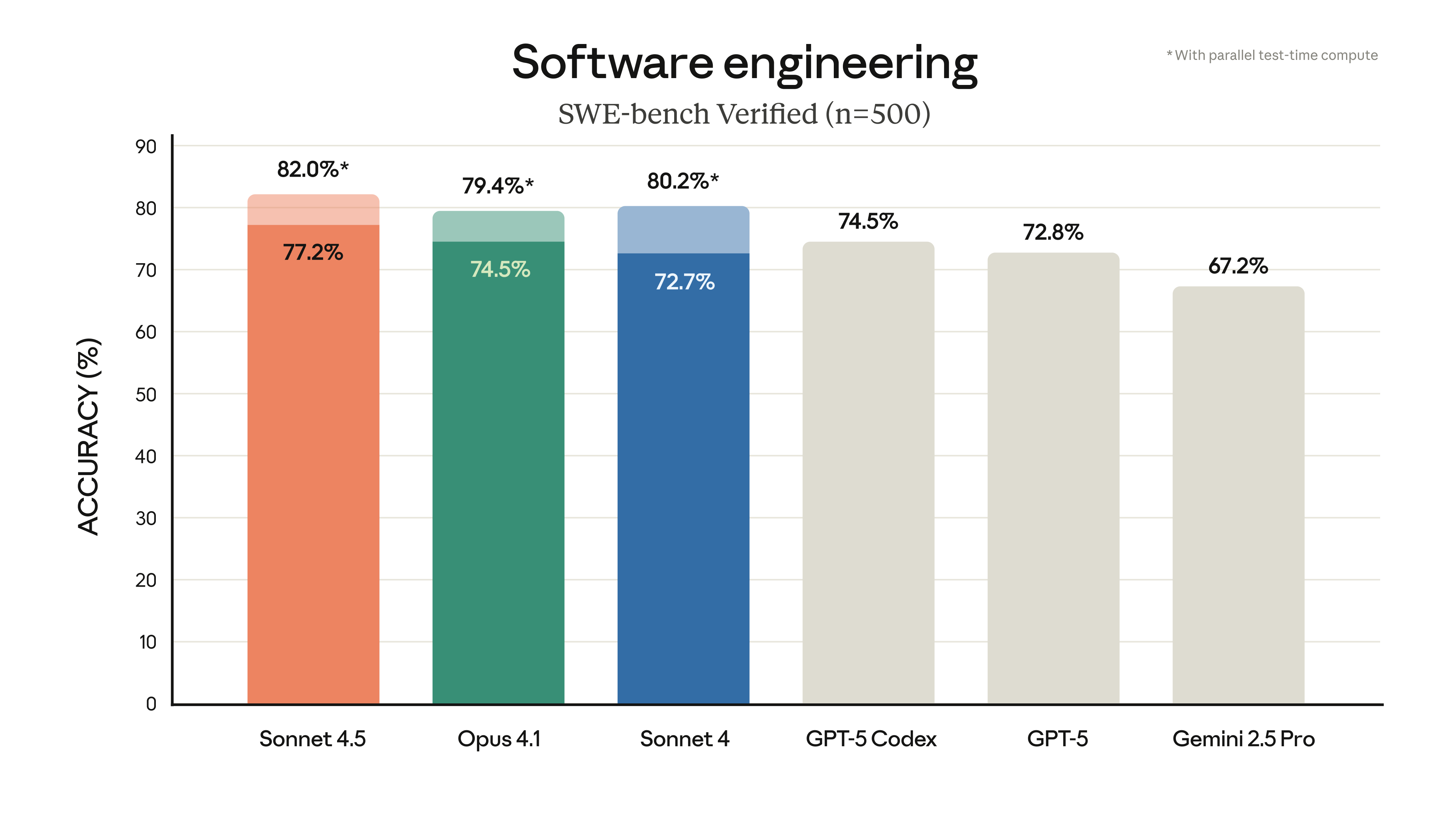
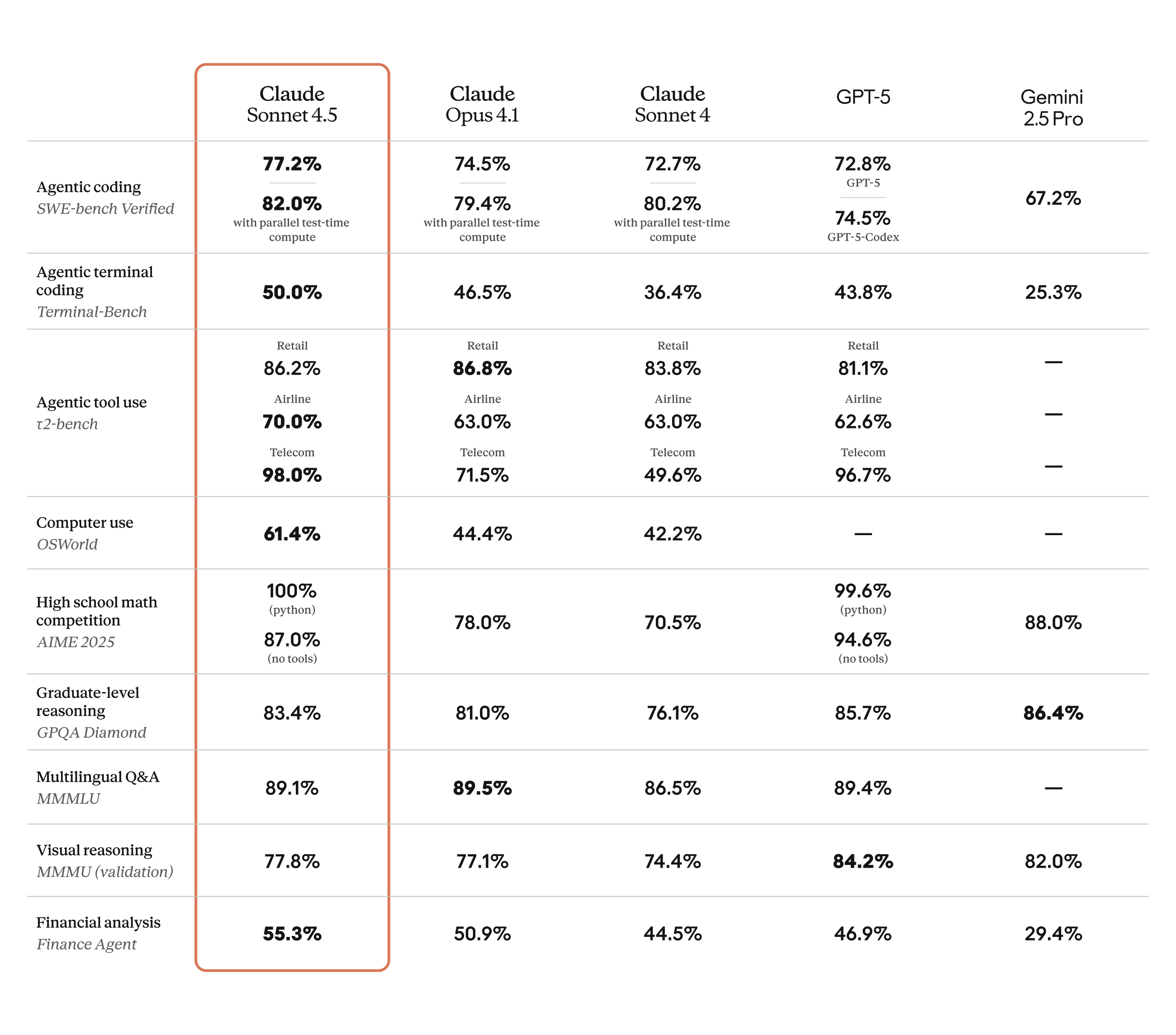
Let’s cut straight to the benchmarks, because that’s what this release is really about. Claude Sonnet 4.5 hits 77.2% on SWE-bench Verified in its standard 200K context configuration — and climbs to an astonishing 82.0% with high-compute parallel processing. For context, GPT-5 Codex sits at 74.5% on the same benchmark. That’s not a marginal win; it’s a statement.
The official announcement from Anthropic also highlights massive gains on OSWorld, the real-world computer use benchmark. Sonnet 4.5 leads at 61.4%, up from Sonnet 4’s 42.2% just four months earlier. That’s a 45% relative improvement in the model’s ability to navigate real desktop environments, click buttons, fill forms, and operate software like a human would.
On mathematical reasoning, the story continues: AIME 2025 scores hit 100% with Python tools (87% without), GPQA Diamond reaches 83.4%, and MMMLU multilingual benchmarks land at 89.1%. These aren’t incremental improvements — they represent a generational leap in what a mid-tier-priced model can accomplish.
30 Hours of Autonomous Focus: What Changed
The headline feature that separates Sonnet 4.5 from everything else on the market is its ability to maintain focused, autonomous work for over 30 hours on complex, multi-step tasks. That’s more than 4x the seven-hour limit of Claude Opus 4, the previous flagship model — and it comes at one-fifth the price.
According to Fortune’s reporting, this isn’t just a theoretical capability. In production use, Sonnet 4.5 demonstrates fewer abandoned reasoning chains, better error recovery, and smarter decisions about when to ask for clarification versus pushing forward independently. The model knows when it’s stuck and acts accordingly — a surprisingly rare trait in autonomous AI agents.
For developers running automated pipelines — like the blog automation system I built with Claude Code — this is transformative. A model that can stay on task for 30+ hours without losing context means you can hand off entire software projects, not just individual functions.
Claude Code 2.0: The Developer Experience Upgrade
Sonnet 4.5 ships alongside Claude Code 2.0, and the developer tooling improvements are substantial:
- Checkpoint system — Save progress at any point, roll back if something goes wrong. No more losing 3 hours of work because the agent took a wrong turn at step 47.
- Native VS Code extension — Direct integration into the IDE most developers already use, with inline suggestions and full agent mode.
- Context editing and memory tools — For extended operations, the model can now manage its own context window more intelligently, prioritizing relevant information.
- File creation in Claude apps — Generate spreadsheets, slides, and documents directly from conversations.
The checkpoint system deserves special attention. Anyone who’s used AI coding agents knows the frustration of a promising 2-hour session going sideways because of one bad decision. Checkpoints mean you can branch, experiment, and revert — essentially giving the AI a version control system for its own reasoning process.
Pricing: The Strategic Masterstroke
Here’s where Anthropic’s strategy becomes crystal clear. Claude Sonnet 4.5 maintains the exact same pricing as Sonnet 4: $3 per million input tokens, $15 per million output tokens. That’s one-fifth the cost of Claude Opus 4.1, while matching or exceeding Opus on most benchmarks.
As TechCrunch reports, this positions Sonnet 4.5 as the default choice for virtually every production use case. Why pay 5x more for Opus when Sonnet matches it on coding, agents, and computer use? The only remaining argument for Opus is edge cases requiring the absolute maximum reasoning depth — and even that gap is narrowing.
For enterprise customers, the economics are staggering. According to Axios, 77% of Claude API prompts now request task automation rather than advisory support, with coding alone accounting for 44% of API usage. At $3/$15 pricing, that’s a fraction of what companies were paying just 18 months ago for comparable capabilities.
Head-to-Head: Claude Sonnet 4.5 vs GPT-5 vs Gemini
The competitive landscape as of September 2025 looks like this:
- Coding: Sonnet 4.5 leads with 77.2% SWE-bench (82% high-compute) vs GPT-5 Codex at 74.5%
- Computer use: Sonnet 4.5 dominates at 61.4% OSWorld — no close competitor
- Math reasoning: Sonnet 4.5 at 100% AIME (with tools), competitive with GPT-5’s best scores
- Multilingual: MMMLU 89.1%, effectively tied with both Opus 4.1 and GPT-5
- Autonomous duration: 30+ hours — nothing else comes close at this price point
- Price: $3/$15 per million tokens — significantly cheaper than GPT-5’s $5/$30 tier
Where GPT-5 still has an edge is in certain creative writing tasks and multimodal understanding. Google’s Gemini Ultra 2 holds advantages in large-context document processing. But for the coding-and-agents use case that represents the majority of enterprise AI spend, Sonnet 4.5 is now the clear price-performance leader.
What This Means for the AI Industry
Sonnet 4.5 signals a broader industry shift: the “smartest” model is no longer necessarily the most expensive one. Anthropic has demonstrated that focused engineering on a mid-tier architecture can match or beat flagship models at a fraction of the cost. This has implications far beyond Anthropic:
- OpenAI will face pressure to either drop GPT-5 pricing or release a comparably priced competitor
- Enterprise buyers can now deploy production-grade AI coding agents without flagship-tier budgets
- Open source models like Llama and Qwen will need to benchmark against Sonnet 4.5’s price-performance, not just raw capability
- AI agent platforms (Devin, Cursor, Windsurf) can now offer better backends at lower operational costs
The era of “premium price equals premium intelligence” is ending. What matters now is the intersection of capability, reliability, and cost — and that’s exactly where Claude Sonnet 4.5 plants its flag.
For developers evaluating their AI stack heading into Q4 2025, the calculus has changed. Sonnet 4.5’s combination of top-tier coding performance, 30-hour autonomous endurance, and unchanged pricing makes it the most compelling default choice for production AI workloads. The question isn’t whether to try it — it’s whether you can afford not to.
Looking to build AI-powered automation pipelines or integrate autonomous coding agents into your workflow?
Get weekly AI, music, and tech trends delivered to your inbox.



{kind=link}
{kind=link}
{kind=link}