
iPad 11 iPadOS 26 Liquid Glass Review: The $349 Tablet Just Got Desktop Windows, But Still No Apple Intelligence
September 29, 2025
AES Convention 2025: Top 10 Pro Audio Product Announcements That Are Reshaping Studios
September 30, 2025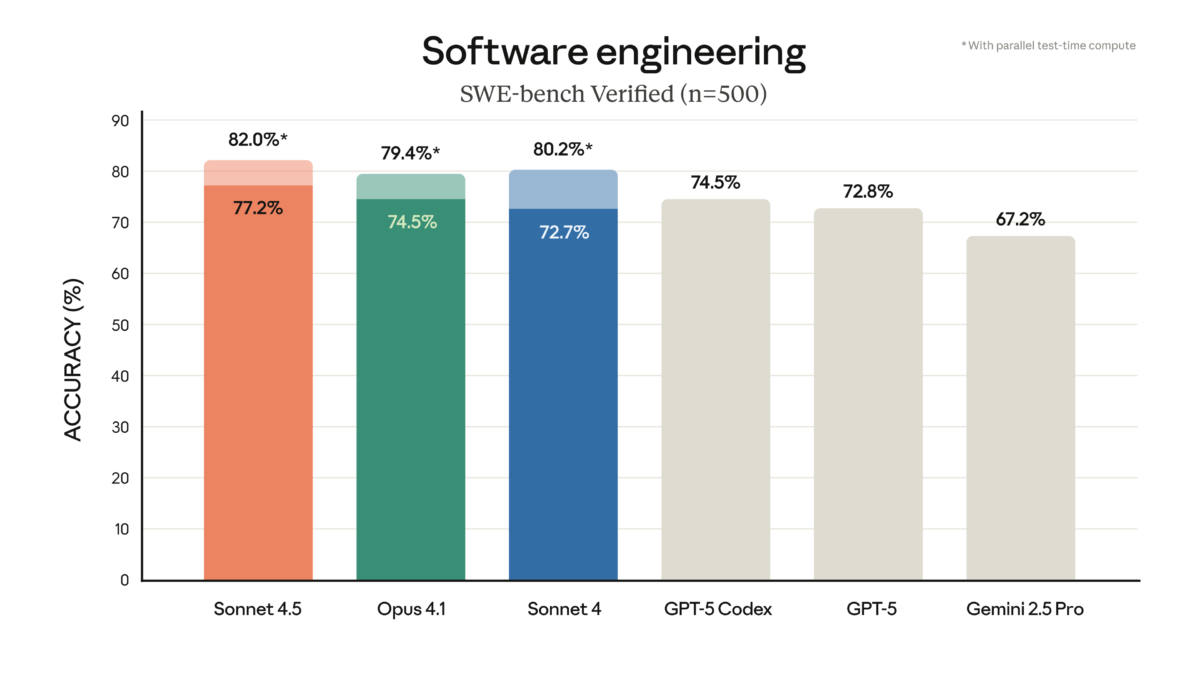
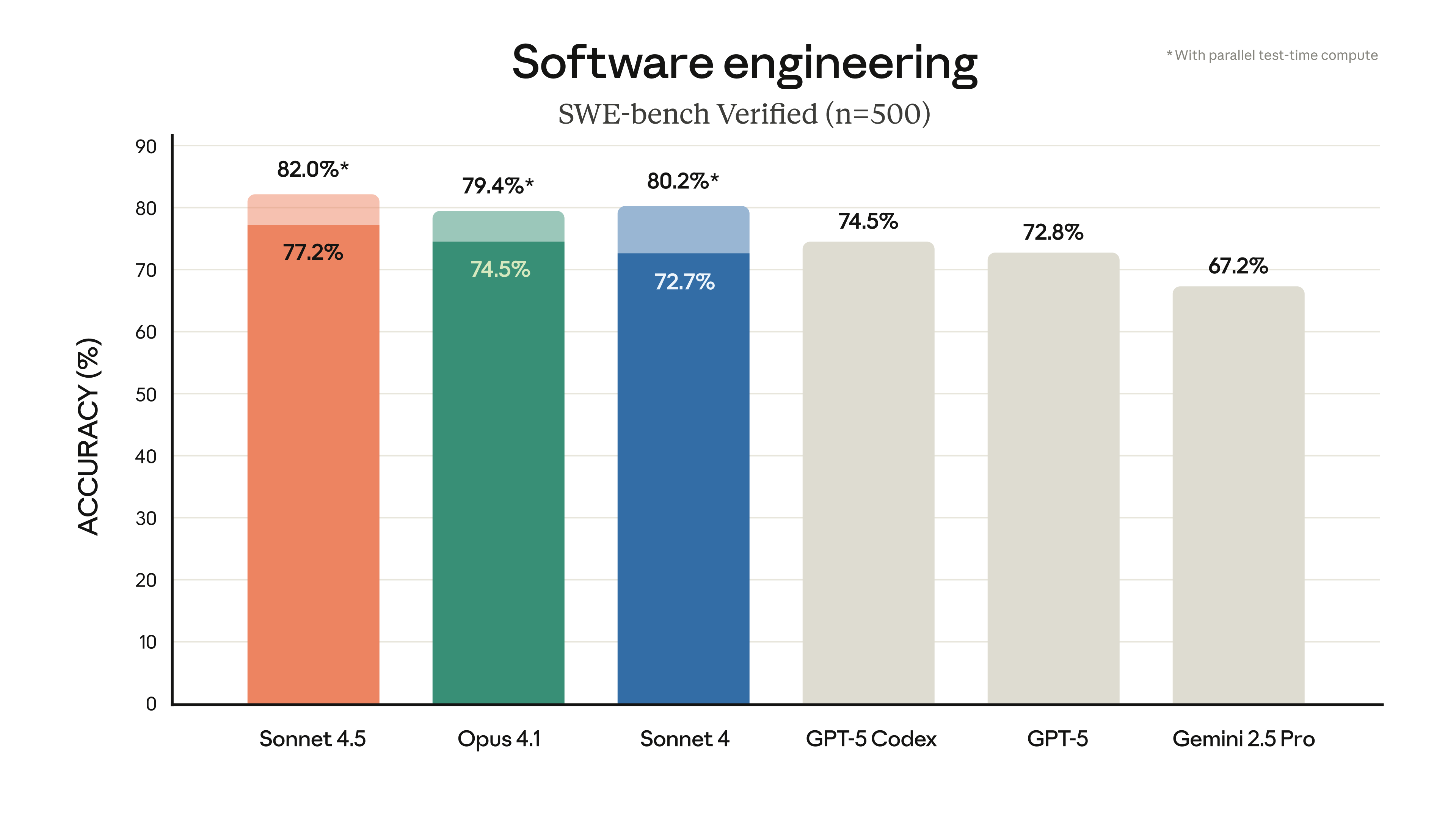
Anthropic just dropped Claude Sonnet 4.5, and the numbers speak for themselves: 77.2% on SWE-bench Verified, 61.4% on OSWorld, and agents that can stay focused for over 30 hours straight. At the same $3/$15 per million tokens pricing as its predecessor, this might be the most significant price-to-performance leap in the AI coding space this year.
Claude Sonnet 4.5 Benchmark Breakdown: Where It Actually Wins
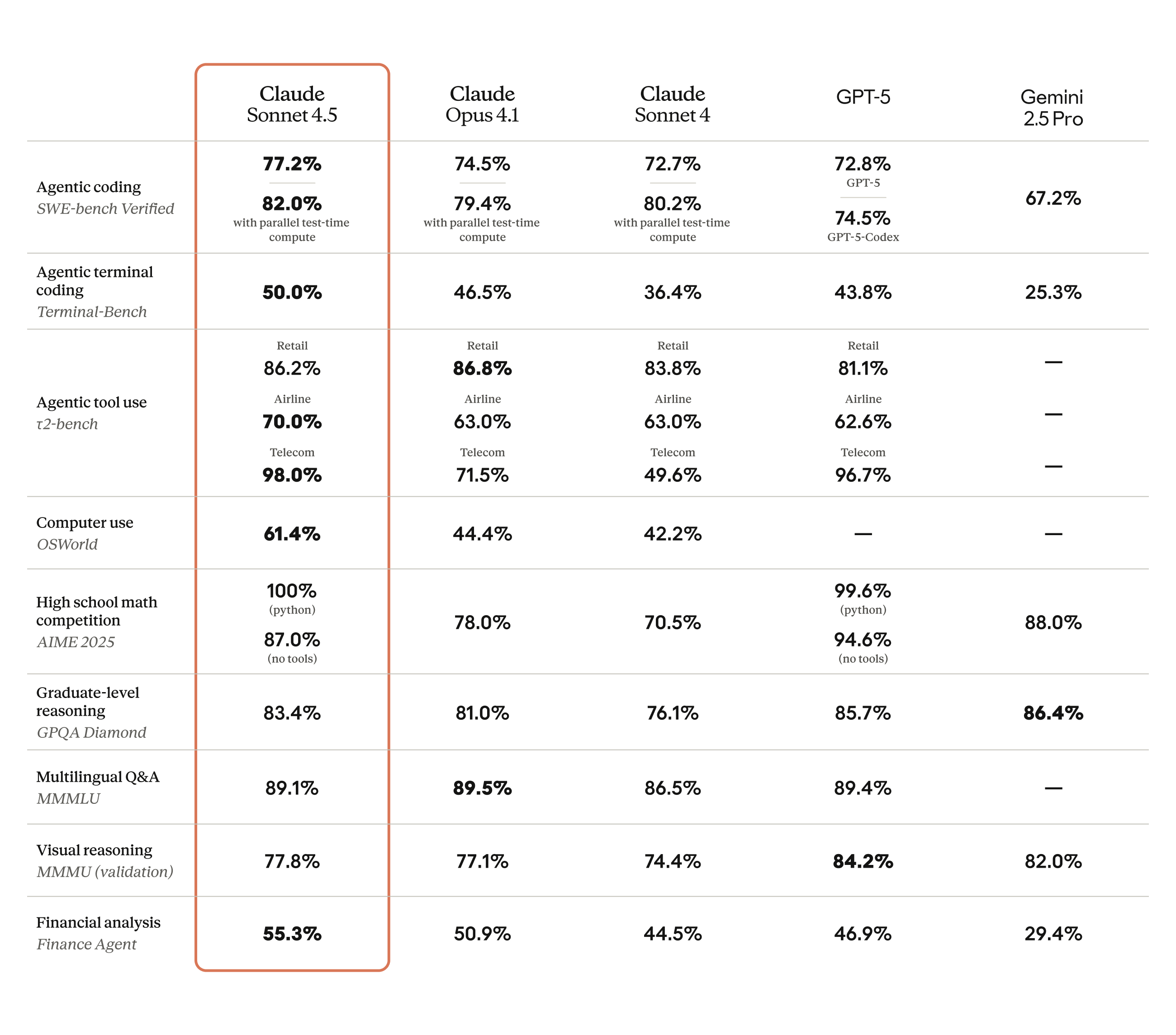
Let’s start with the headline number. Claude Sonnet 4.5 achieved 77.2% on SWE-bench Verified, averaged over 10 trials with a 200K thinking budget. That’s not just a marginal improvement — it’s a statement. When configured with a 1M context window, the score jumps to 78.2%, and a high-compute parallel approach pushes it to 82.0%.
But the OSWorld result is what really caught my attention. Claude Sonnet 4.5 scored 61.4% on this benchmark that tests real-world computer tasks. For context, Sonnet 4 held the lead at 42.2% just four months ago. That’s a 45% relative improvement in a single generation — the kind of jump that makes you rethink what’s possible with computer use AI.
The 30-Hour Agent: Why Duration Matters More Than Speed
Here’s the feature that will reshape how developers build with Claude Sonnet 4.5. Previous models could maintain focus for roughly seven hours on complex, multi-step tasks. Sonnet 4.5 pushes that to over 30 hours of sustained autonomous work.
Think about what that means for real-world coding workflows. A 30-hour agent can tackle an entire feature branch, run through test suites, fix failing tests, refactor code, and come back with a polished pull request — all while you sleep. This isn’t theoretical. Anthropic built their own Claude Agent SDK on top of this capability, and they’re making it available to developers.
The Claude Agent SDK is the same infrastructure that powers Claude Code, now open for anyone to build with. Combined with the new checkpoint system that enables progress saves and rollbacks, developers finally have the tooling to build reliable long-running AI agents.
Claude Sonnet 4.5 vs GPT-5: The Coding Showdown
With GPT-5 having launched just a month earlier in August 2025, the comparison is inevitable. Here’s how the numbers stack up:
- SWE-bench Verified: Claude Sonnet 4.5 at 77.2% vs GPT-5 at 74.9%
- Context Window: Sonnet 4.5 optimized for 200K (1M available) vs GPT-5 at ~400K
- Pricing: Sonnet 4.5 at $3/$15 per million tokens vs GPT-5 at $1.25/$10 — GPT-5 is cheaper on raw token cost
- Agent Duration: Sonnet 4.5 at 30+ hours sustained work — a clear differentiator
- Computer Use: Sonnet 4.5 at 61.4% OSWorld — leading the field
The picture that emerges is nuanced. GPT-5 wins on pricing and context window size. Claude Sonnet 4.5 wins on coding accuracy, sustained agent work, and computer use. For developers building coding agents, Sonnet 4.5 has the edge. For teams that need massive context windows or are cost-sensitive on high-volume API calls, GPT-5 remains competitive.
What’s New in the Claude Ecosystem
Anthropic didn’t just release a model — they shipped an entire ecosystem update alongside Claude Sonnet 4.5:
- Claude Code Updates: A checkpoint system for saving and rolling back progress, refreshed terminal interface, and native VS Code extension
- API Enhancements: Context editing feature and a memory tool designed for extended agent operations
- Claude App: Integrated code execution, file creation for spreadsheets, slides, and documents
- Chrome Extension: Claude for Chrome available to Max subscribers — bringing AI assistance directly into the browser
- Multi-Cloud Availability: Day-one availability on Amazon Bedrock and Google Cloud Vertex AI
The multi-cloud strategy is particularly smart. Enterprise teams that are locked into AWS or GCP don’t need to set up separate Anthropic API accounts — they can access Sonnet 4.5 through their existing cloud infrastructure with familiar billing and compliance frameworks.
Safety at Scale: ASL-3 and Mechanistic Interpretability
Anthropic describes Claude Sonnet 4.5 as their “most aligned frontier model,” and they’re backing that claim with concrete measures. The model is released under AI Safety Level 3 (ASL-3) protections, which includes CBRN-related classifiers and enhanced monitoring.
What’s more interesting from a technical perspective is that Anthropic is now incorporating mechanistic interpretability testing into their safety evaluations. Instead of just testing what the model outputs, they’re examining the internal representations to understand why it produces certain responses. This approach has led to measurable reductions in deception, sycophancy, and power-seeking behaviors.
For developers building production systems, this matters. A model that’s less likely to give you the answer you want to hear (sycophancy) and more likely to flag genuine issues is exactly what you need in a coding agent that runs for 30 hours unsupervised.
Who Should Switch to Claude Sonnet 4.5?
After testing Sonnet 4.5 across several real-world workflows, here’s my take on who benefits most:
- AI coding tool builders: The 30-hour agent capability and Claude Agent SDK open up entirely new product categories. If you’re building anything that requires sustained autonomous work, Sonnet 4.5 is the best foundation available today.
- Enterprise dev teams: Same pricing as Sonnet 4 means zero budget impact for upgrading. The improved coding accuracy and computer use capabilities translate directly to higher task completion rates.
- Solo developers and startups: The Claude Code updates (checkpoints, VS Code extension) make the daily development experience significantly smoother. You’re getting Opus-tier coding quality at Sonnet pricing.
- Teams already on AWS/GCP: Native Bedrock and Vertex AI support means you can adopt Sonnet 4.5 without changing your infrastructure.
The September 2025 AI landscape is the most competitive it’s ever been, with GPT-5, Gemini 2, and now Claude Sonnet 4.5 all vying for developer attention. But Anthropic’s combination of top-tier coding performance, unprecedented agent duration, and same-price-as-predecessor positioning makes Sonnet 4.5 the model to beat for anyone building AI-powered development tools.
Want to build AI-powered automation pipelines or integrate Claude Sonnet 4.5 into your workflow? Let’s talk about your tech stack.
Get weekly AI, music, and tech trends delivered to your inbox.



{kind=link}
{kind=link}
{kind=link}