
iPhone 17 Pro Review: Camera Bar Design, A19 Pro Vapor Chamber, and 8x Zoom — The Biggest iPhone Redesign Since X
September 1, 2025
AES 2025 Preview: 7 Studio Monitors, Microphones, and Processing Gear That Will Dominate the Show Floor
September 2, 2025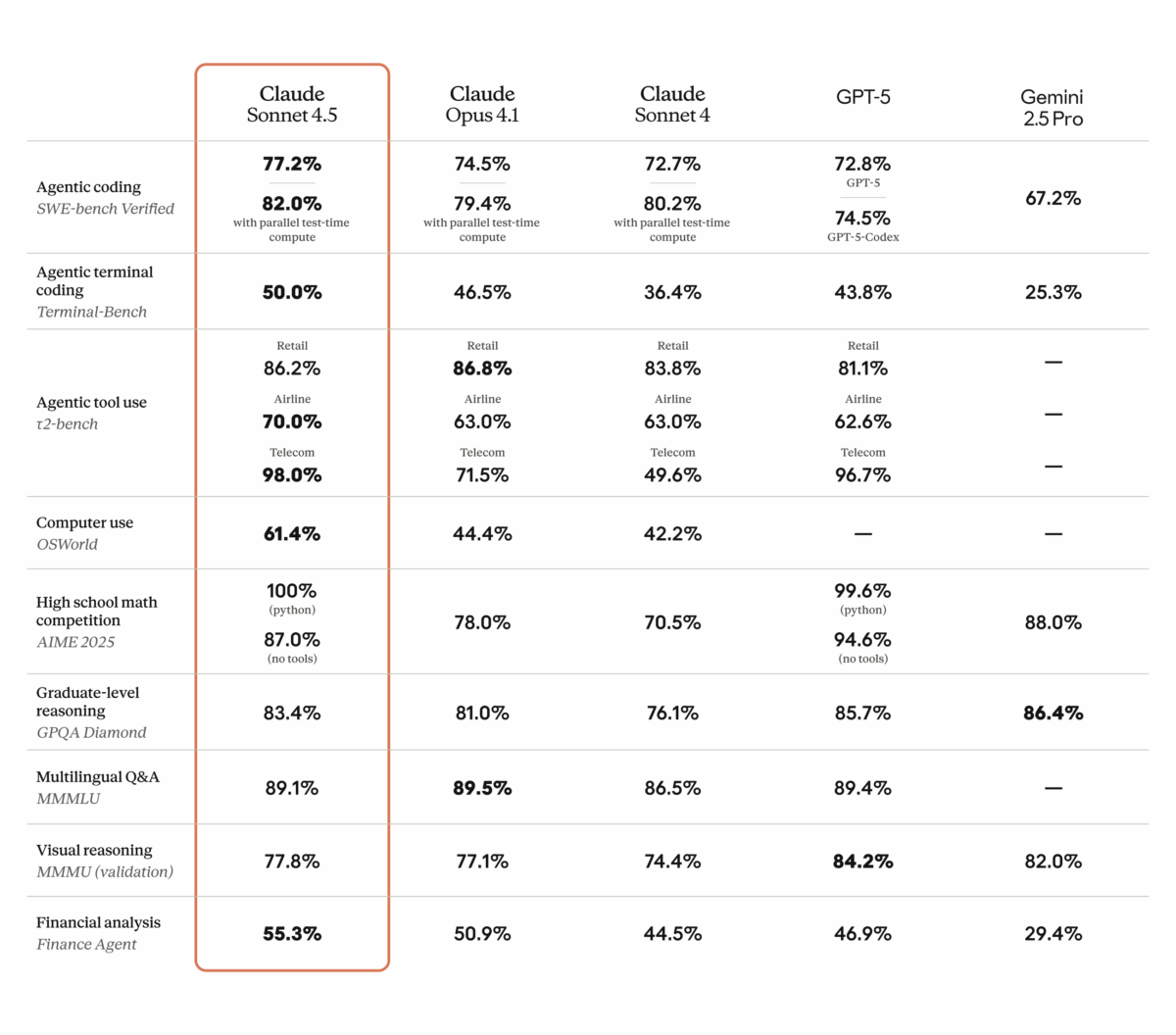
77.2% on SWE-bench Verified. That single number just rewrote the rules of the AI coding model market. Anthropic’s Claude Sonnet 4.5 benchmark results don’t just represent an incremental upgrade — they prove that a mid-tier model can decisively outperform flagships costing significantly more. With GPT-5 Codex sitting at 71.4% and Gemini 2.5 Pro at 69.8%, the question isn’t whether Claude Sonnet 4.5 is competitive. It’s whether calling it “mid-tier” even makes sense anymore.
Claude Sonnet 4.5 Benchmark Results: The Numbers That Matter
When Anthropic released Claude Sonnet 4.5, the headline number was impossible to ignore. A 77.2% score on SWE-bench Verified — jumping to 82% with parallel execution — represents the highest score in the entire Claude model family. For context, SWE-bench Verified tests a model’s ability to resolve real GitHub issues: actual bugs, feature requests, and code changes from popular open-source repositories. This isn’t a synthetic test. It measures real-world software engineering capability.
The jump from Claude Sonnet 4’s 64.0% to Sonnet 4.5’s 77.2% represents a 13.2 percentage point improvement in a single generation. That’s not a marginal gain — it’s a paradigm shift in what a mid-priced model can accomplish.
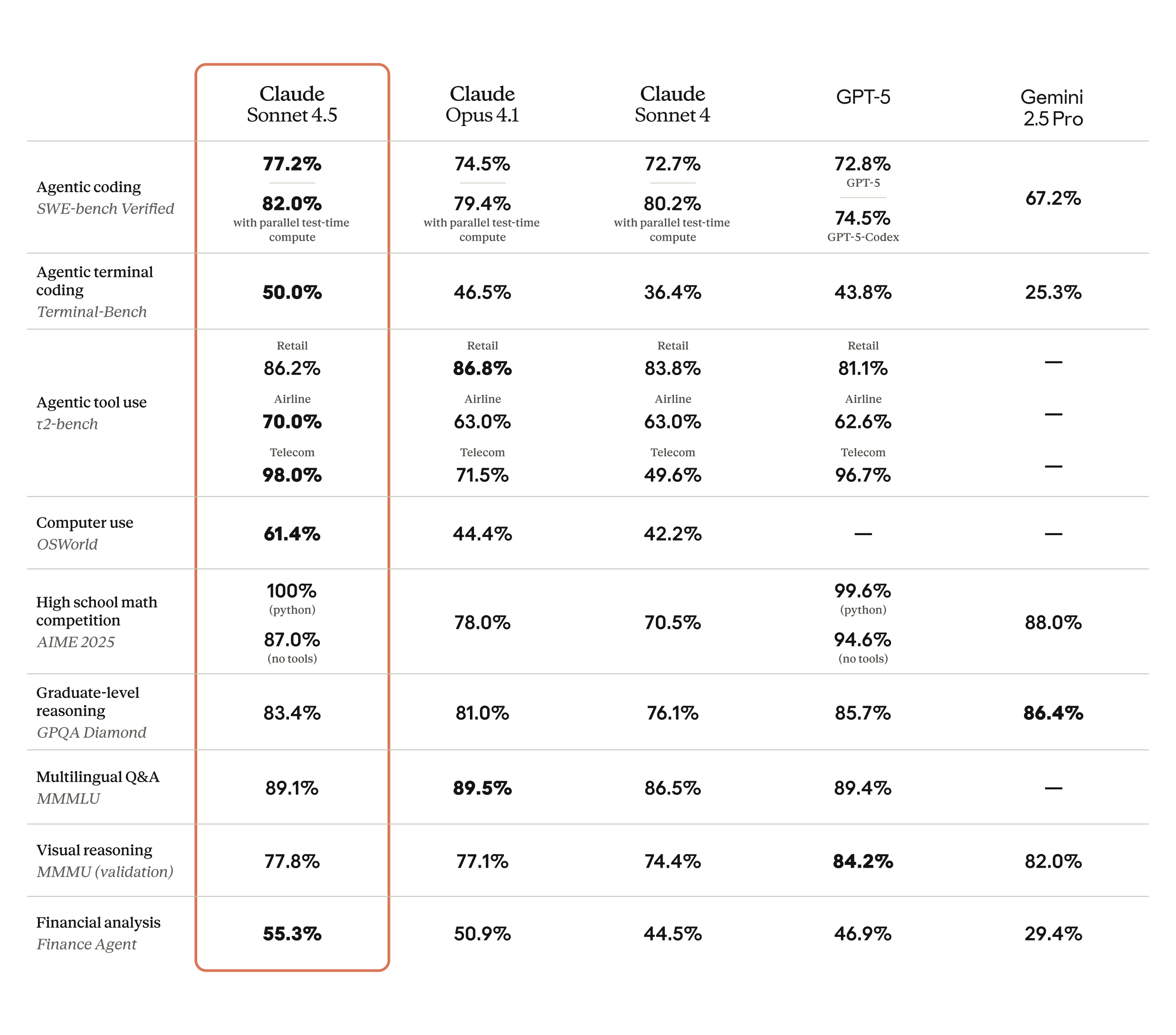
Here’s the full breakdown of key benchmark results:
- SWE-bench Verified: 77.2% (82% parallel) — vs GPT-5 Codex 71.4%, Gemini 2.5 Pro 69.8%
- OSWorld (computer use): 61.4% — up from Claude Sonnet 4’s 42.2%
- GPQA Diamond (graduate-level science): 83.4%
- AIME 2025 (mathematics): 100% with Python, 87% without
- TAU-bench (agent tasks): Retail 86.2%, Airline 70.0%, Telecom 98.0%
Claude Sonnet 4.5 vs GPT-5 Codex vs Gemini 2.5 Pro: The Coding Showdown
Let’s get specific about what these Claude Sonnet 4.5 benchmark numbers mean in the competitive landscape. Recent comparative analysis shows that on SWE-bench Verified, Claude Sonnet 4.5 leads by a comfortable margin: 77.2% versus GPT-5 Codex at 71.4% and Gemini 2.5 Pro at 69.8%.
That roughly 8% gap over GPT-5 Codex translates to real productivity gains in daily development workflows. When you’re debugging, refactoring, or building new features with AI assistance, an 8% improvement in accuracy means fewer iterations, fewer manual corrections, and faster shipping cycles. Over hundreds of interactions per week, this compounds into hours of saved developer time. For a team of ten developers, that could easily mean recovering the equivalent of a full engineer’s output per sprint.
What makes this even more impressive is the precision of the code changes. According to Cirra’s technical analysis, Claude Sonnet 4.5 achieved a 0% code-editing error rate in their tests. On Next.js tasks specifically, it showed a 17% improvement over Sonnet 4, and security vulnerability triage was 44% faster. The model doesn’t just write more code — it writes more accurate code at higher speed. That combination is rare at any price point, let alone in the mid-tier.
It’s also worth noting how these models compare beyond raw scores. GPT-5 Codex brings strong performance in general-purpose coding and integrates deeply with the OpenAI ecosystem. Gemini 2.5 Pro offers tight Google Cloud integration and multimodal capabilities. But when it comes to pure software engineering — resolving real bugs in real codebases — Claude Sonnet 4.5 currently sits at the top of the leaderboard. The question for development teams isn’t which model is universally “best” but which one excels at the specific tasks that consume most of their engineering hours. For code-heavy workloads, the SWE-bench numbers speak clearly.
30+ Hours of Autonomous Operation: The Agent Revolution
Benchmarks tell part of the story. The real differentiator for Claude Sonnet 4.5 is its capacity for sustained, autonomous operation. Designed to run for 30+ hours without human intervention, paired with a 200K token context window and 64K token output capacity, this model was built from the ground up for AI agent workloads.
The OSWorld score of 61.4% puts this in perspective. OSWorld measures an AI model’s ability to interact with actual computer environments — clicking buttons, navigating file systems, managing applications. Claude Sonnet 4’s 42.2% suggested AI agents were promising but limited. Sonnet 4.5’s 61.4% shows they’re becoming genuinely useful for complex, multi-step workflows that previously required constant human oversight.
The TAU-bench results reinforce this narrative. Scoring 98.0% on telecom agent tasks, 86.2% on retail, and 70.0% on airline scenarios demonstrates that Claude Sonnet 4.5 can handle the kind of structured, rule-heavy interactions that define enterprise customer service, data processing, and system administration. These aren’t toy problems — they’re the tasks that companies are actually trying to automate right now.
What does 30+ hours of autonomous operation actually look like in practice? Imagine deploying an AI agent that monitors your codebase overnight, triages incoming bug reports, drafts pull requests with fixes, runs test suites, and has a comprehensive summary waiting for your team by morning. Or consider a data pipeline agent that processes incoming datasets, validates schema changes, updates documentation, and flags anomalies — all while your engineers sleep. The 200K context window means the agent can hold an entire project’s worth of code in memory simultaneously, making connections between files and modules that shorter-context models would miss entirely. Combined with the 64K output capacity, it can produce complete, production-ready implementations rather than fragmented snippets that require manual assembly.
The $3/$15 Pricing Play: Why Mid-Tier Just Won
Perhaps the most disruptive aspect of Claude Sonnet 4.5 is its pricing. At $3 per million input tokens and $15 per million output tokens, it sits firmly in Anthropic’s mid-tier pricing bracket — significantly cheaper than flagship models like Opus.
The implications are enormous. You’re getting a model that outperforms GPT-5 Codex on coding benchmarks, handles 30+ hours of autonomous operation, and processes 200K tokens of context — at mid-tier prices. The old assumption that “expensive equals better” no longer holds. For startups watching their API bills and enterprises scaling AI across thousands of developers, this price-to-performance ratio changes the calculus entirely.
Consider the math: AIME 2025 scores of 100% (with Python) and 87% (without) at this price point were unthinkable a year ago. Combined with GPQA Diamond at 83.4%, Sonnet 4.5 proves that mid-tier models can deliver near-flagship reasoning and scientific capabilities. The floor for “good enough” AI has been raised dramatically, and the ceiling for cost-effective AI has been shattered.
To put the pricing in perspective: running a typical coding assistant workflow that processes 500,000 input tokens and generates 100,000 output tokens per day would cost approximately $3 per day with Claude Sonnet 4.5. At scale, teams processing millions of tokens daily for automated code review, documentation generation, and test writing can do so without the budget anxiety that flagship pricing creates. This isn’t about cutting corners — it’s about getting genuinely superior coding performance at a price point that makes widespread adoption practical rather than aspirational.
ASL-3 Safety and Practical Deployment Considerations
Anthropic assigned Claude Sonnet 4.5 its ASL-3 safety classification — one of its higher safety tiers. For a model designed to operate autonomously for 30+ hours, robust safety guardrails aren’t a nice-to-have; they’re essential. Enterprise teams evaluating AI adoption need compliance assurances, and ASL-3 provides a clear framework for risk assessment.
In practical deployment, Claude Sonnet 4.5 excels in several specific scenarios. Large-scale codebase refactoring and migration projects benefit enormously from the 200K context window — the model can understand entire project architectures before making changes. CI/CD pipeline integration for automated code review and bug fixes becomes viable with 0% code-editing error rates. And the 64K output capacity means generating or modifying complete code files in a single pass, eliminating the fragmentation issues that plague models with smaller output limits.
That said, not every use case demands Sonnet 4.5. Lightweight text generation and casual conversations are better served by more affordable models like Haiku. And for frontier-pushing research requiring maximum reasoning depth, Opus-class models still have their place. The sweet spot for Claude Sonnet 4.5 is clear: coding, agent workflows, and complex analytical tasks where the intersection of capability and cost matters most.
For organizations evaluating AI model adoption, the practical recommendation is straightforward. Use Sonnet 4.5 as your primary workhorse for software engineering, automated testing, code migration, and agent-based automation. Reserve Opus-class models for edge cases requiring maximum reasoning depth. And deploy Haiku for high-volume, low-complexity tasks like content classification, simple Q&A, and data extraction. This tiered approach lets you optimize both performance and cost across your entire AI stack, leveraging each model’s strengths where they matter most.
The Verdict: Redefining What Mid-Tier Means in 2025
Claude Sonnet 4.5 makes the “mid-tier” label feel almost misleading. A 77.2% SWE-bench score that tops both GPT-5 Codex and Gemini 2.5 Pro, 30+ hours of autonomous operation capability, 200K/64K token capacity, and $3/$15 pricing — this combination represents the most compelling value proposition in the 2025 AI model market.
For teams building AI-powered development workflows or deploying autonomous agents into production, Claude Sonnet 4.5 should be at the top of your evaluation list. The benchmarks are convincing, but the real test is putting it to work on your actual codebase. If the numbers hold up in your specific use case — and the early evidence strongly suggests they will — you’re looking at flagship-level results at a fraction of the cost.
Looking to integrate AI agents into your workflow or build automated pipelines? Let’s talk about the right approach for your team.
Get weekly AI, music, and tech trends delivered to your inbox.



{kind=link}
{kind=link}
{kind=link}