
iPhone 17 Rumors: Camera Bar Design, A19 Pro Chip, and 7 Major Changes Coming in September
August 8, 2025
Best Audio Interfaces for Podcasters August 2025: Top 5 USB-C Picks
August 11, 2025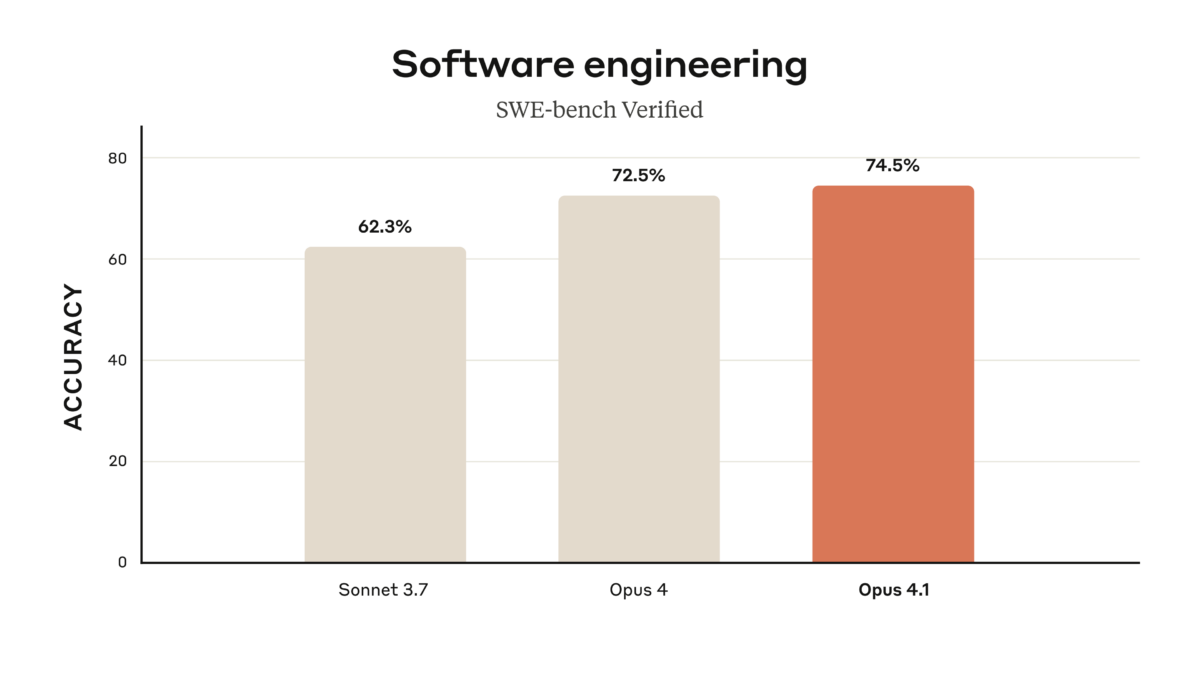
Two days. That’s all it took for the AI landscape to completely shift. On August 5, Anthropic dropped Claude Opus 4.1. On August 7, OpenAI fired back with GPT-5. If you’re a developer, content creator, or business leader trying to decide which model deserves your API budget, this is the most consequential week of 2025 so far — and I’ve spent the last 72 hours stress-testing both to give you the real answer on Claude Opus 4.1 vs GPT-5.
Claude Opus 4.1 vs GPT-5: The August 2025 Showdown by the Numbers
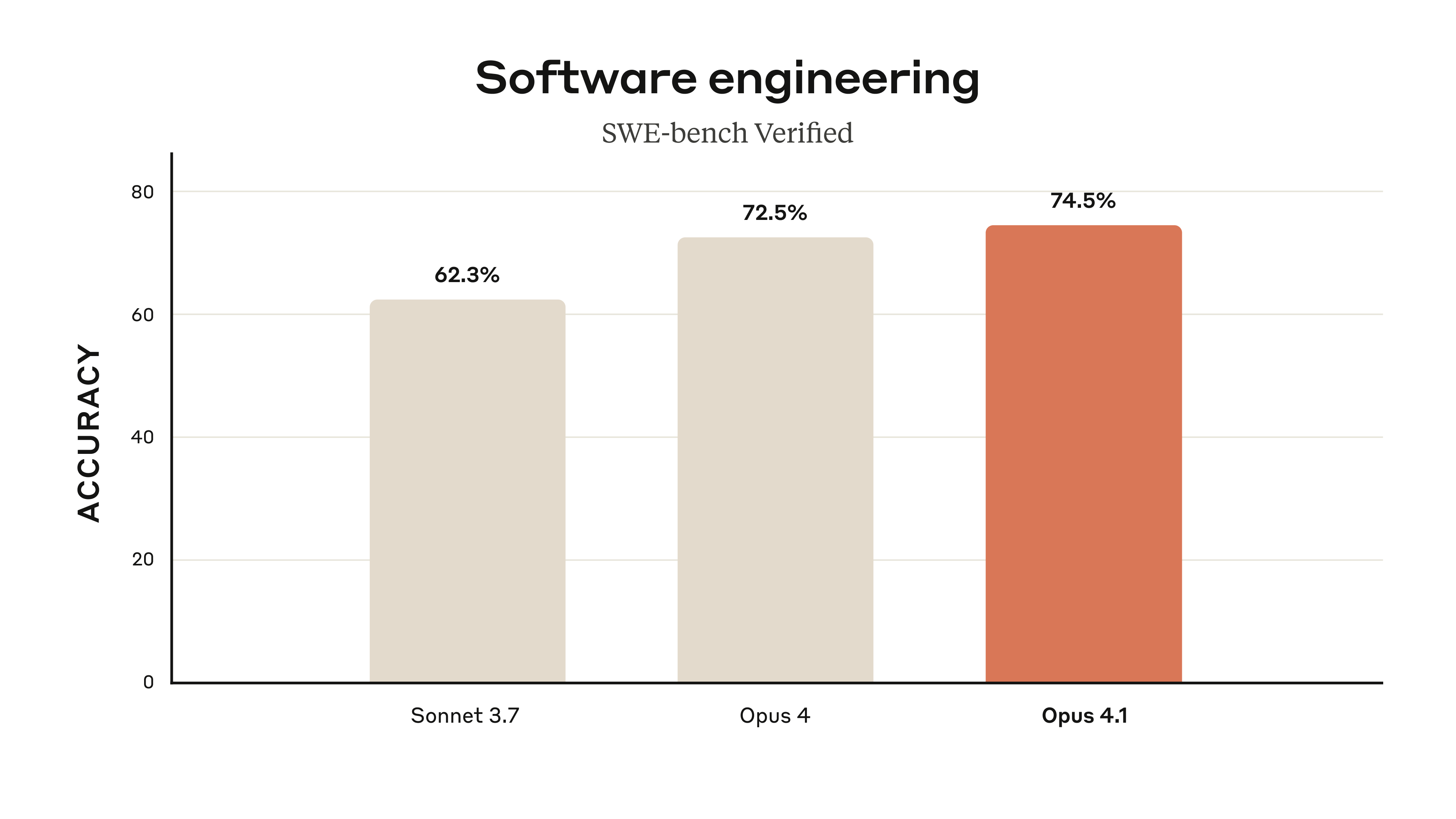
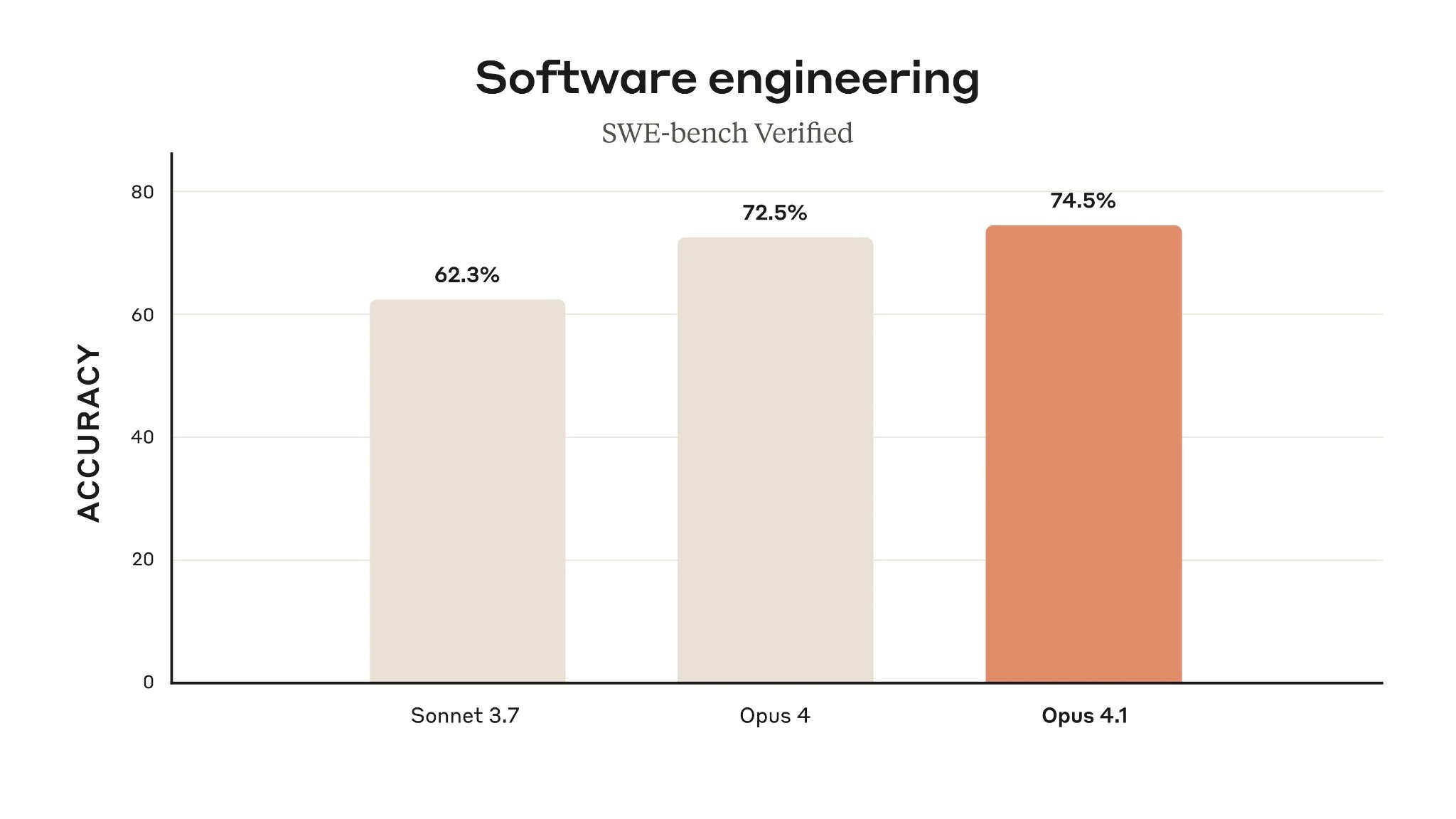
Let’s cut straight to the benchmarks that matter. Both models landed within striking distance on SWE-bench Verified, the industry standard for real-world coding ability — Claude Opus 4.1 scored 74.5%, while GPT-5 edged ahead at 74.9%. That 0.4% gap is practically noise. But the story gets far more interesting when you zoom out.
GPT-5 dominates mathematics with a stunning 94.6% on AIME 2025 (without tools), and its multimodal understanding hits 84.2% on MMMU. Claude Opus 4.1, meanwhile, pushed its Terminal-Bench performance from 39.2% to 43.3% and raised its harmless response rate to an industry-leading 98.76%. These aren’t just numbers — they reveal fundamentally different design philosophies.
Architecture and Design Philosophy: Two Very Different Approaches
OpenAI built GPT-5 as a unified system with a smart router that dynamically decides between a fast model for simple queries and a deeper reasoning model (GPT-5 thinking) for complex problems. This architecture means you get speed when you need it and depth when the problem demands it — all through a single API endpoint.
Anthropic took the incremental route with Opus 4.1. Rather than a ground-up rebuild, they focused on strengthening what Opus 4 already did well: multi-file refactoring, agentic reasoning, and state tracking over extended interactions. As InfoQ reported, the improvements target software engineering workflows where developers need reliable code refactoring across complex codebases.
The practical difference? GPT-5 feels like a Swiss Army knife — one tool that adapts to everything. Claude Opus 4.1 feels like a precision instrument — specialized, thorough, and methodical. Both approaches have merit, and your preference will depend entirely on your use case.
Coding Performance: The Real-World Developer Verdict
Here’s where the Claude Opus 4.1 vs GPT-5 comparison gets spicy. According to Composio’s head-to-head coding comparison, GPT-5 uses approximately 90% fewer tokens to solve the same algorithmic problems. That’s not a typo — ninety percent. For the median of two sorted arrays problem, Claude Opus 4.1 burned through ~79,000 tokens and took ~34 seconds, while GPT-5 delivered the same correct solution with minimal extraneous output.
But here’s the twist: when it came to visual design fidelity — say, replicating a pixel-perfect UI from a mockup — Claude Opus 4.1 produced results that matched the design almost perfectly, despite initially struggling with configuration. GPT-5 was faster but less visually precise.
My takeaway after running both through production-grade tasks: GPT-5 is your everyday workhorse for algorithms, prototyping, and rapid iteration. Claude Opus 4.1 is what you reach for when you need thorough analysis, detailed code review, or pixel-perfect execution. The smartest developers I know are already using both — building core logic with GPT-5, then running quality passes with Claude.
The Pricing Gap That Changes Everything
This is where the conversation gets uncomfortable for Anthropic. As TechCrunch reported, OpenAI priced GPT-5 so aggressively that it may have ignited a price war. The numbers speak for themselves:
- GPT-5: $1.25/M input tokens, $10/M output tokens
- Claude Opus 4.1: $15/M input tokens, $75/M output tokens
- The gap: GPT-5 is 12x cheaper on input and 7.5x cheaper on output
OpenAI also offers gpt-5-mini at $0.25/M input and gpt-5-nano at $0.05/M input — tiers that make Claude’s pricing look from another era. Add in GPT-5’s revolutionary 90% discount on cached tokens, and the total cost of ownership gap widens even further for high-volume applications.
GPT-5 also ships with a 400K token context window and 128K maximum output — double Claude’s 200K context. For enterprise workflows processing large documents or maintaining extended conversation histories, this alone can be decisive.
Safety and Reliability: Where Claude Still Leads
Anthropic has always positioned safety as Claude’s core differentiator, and Opus 4.1 delivers. The 98.76% harmless response rate (up from 97.27% in Opus 4) is the highest in the industry. For regulated industries — healthcare, finance, legal — this isn’t just a nice-to-have, it’s a compliance requirement.
GPT-5 reduced hallucinations by approximately 45% compared to GPT-4o, and by 80% when using the thinking mode. That’s impressive progress, but OpenAI hasn’t published comparable safety benchmark numbers, making direct comparison difficult. If your use case demands maximum reliability on sensitive outputs, Claude Opus 4.1 currently has the more transparent safety story.
Who Should Use Which Model? The Decision Framework
After extensive testing, here’s my honest recommendation framework for Claude Opus 4.1 vs GPT-5:
Choose GPT-5 If You:
- Need maximum token efficiency and speed for everyday development
- Process large documents (400K context window advantage)
- Are budget-conscious — 12x cheaper input pricing is hard to ignore
- Require strong math reasoning (94.6% AIME is class-leading)
- Want a single endpoint that auto-routes between fast and deep reasoning
Choose Claude Opus 4.1 If You:
- Need thorough, methodical code review and multi-file refactoring
- Work in regulated industries requiring maximum safety guarantees
- Value detailed explanations and verification in outputs
- Build agentic workflows that require reliable state tracking
- Prioritize visual design accuracy over raw speed
Use Both If You:
- Can afford a dual-model workflow (and honestly, you probably can — the combined cost is still lower than Opus alone for most use cases)
- Want to build with GPT-5 and polish with Claude
- Need to validate critical outputs by cross-checking between models
The Bottom Line: August 2025’s AI Verdict
The release of GPT-5 and Claude Opus 4.1 within 48 hours of each other crystallizes a truth about the AI market in 2025: there is no single “best” model anymore. GPT-5 wins on efficiency, pricing, and raw mathematical reasoning. Claude Opus 4.1 wins on thoroughness, safety, and specialized coding workflows. The era of blindly picking one provider is over — the smartest teams are building model-agnostic architectures that leverage the strengths of each.
What’s clear is that OpenAI’s aggressive pricing puts real pressure on Anthropic. At 12x the cost per input token, Claude Opus 4.1 needs to deliver dramatically superior results to justify its premium — and while it does in specific scenarios, the gap isn’t wide enough for most general-purpose applications. If Anthropic doesn’t respond with pricing adjustments or a compelling mid-tier offering, GPT-5 will dominate enterprise adoption through sheer economics.
For now, my recommendation is simple: start with GPT-5 for the 80% of tasks where speed and cost matter most, and keep Claude Opus 4.1 in your toolkit for the 20% where precision and safety are non-negotiable. That’s not a compromise — it’s how the best AI-powered teams will operate for the rest of 2025.
Need help building AI-powered automation pipelines or choosing the right model for your workflow? Let’s talk strategy.
Get weekly AI, music, and tech trends delivered to your inbox.



{kind=link}
{kind=link}
{kind=link}