Samsung Unpacked 2025 Complete Roundup: Galaxy Z Fold 7, Z Flip 7, and Watch 8 — 5 Products, All the Details
August 7, 2025
iZotope Nectar 4 Summer Update: AI Vocal Chain Gets New Presets and 3 Modules That Change Everything
August 8, 2025
Claude Opus 4.1 just dropped three days ago, and the benchmark numbers are telling a story that every developer building on AI should pay attention to — 74.5% on SWE-bench Verified, 64K tokens of extended thinking, and multi-file refactoring that actually works. This isn’t a press release you skim and forget. If you’re shipping production code with AI assistance, what Anthropic changed under the hood matters more than the headline numbers suggest.
Claude Opus 4.1: What Anthropic Shipped on August 5th
On August 5, 2025, Anthropic quietly released Claude Opus 4.1 (model ID: claude-opus-4-1-20250805), an iterative upgrade to their flagship model. This isn’t a generational leap — it’s a surgical refinement. The kind of update that matters most when you’re deep in production code and need your AI assistant to keep up with real-world complexity.
The model is available everywhere you’d expect: the Anthropic API, Claude.ai, Claude Code, Amazon Bedrock, and Google Vertex AI. Pricing stays identical to Opus 4 — $15 per million input tokens, $75 per million output tokens. Same context window at 200K tokens, same 32K output token limit. For teams already running Opus 4 in production, this is effectively a free performance boost with zero migration cost.
What makes this release interesting isn’t any single benchmark improvement — it’s the pattern. Anthropic targeted the exact pain points that developers report most: cross-file code changes breaking, long debugging sessions losing context, and extended reasoning chains producing confident-sounding nonsense. Let’s dig into what actually moved.
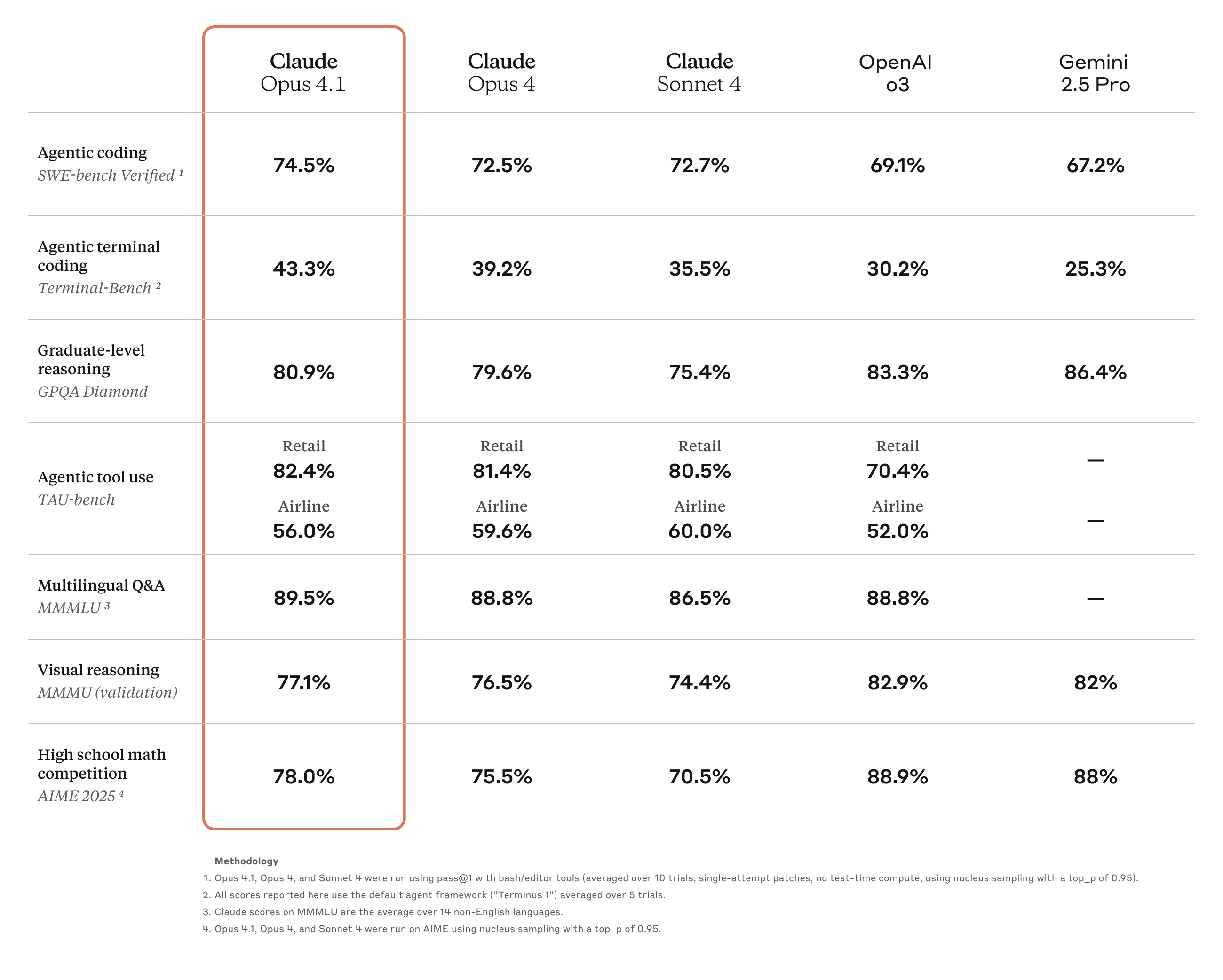
The Benchmark Numbers: Where Claude Opus 4.1 Actually Improved
Let’s break down the numbers that matter. As Simon Willison detailed in his coverage, the improvements are consistent across most benchmarks, though the magnitude varies considerably by category.
SWE-bench Verified: 72.5% → 74.5%
The headline number. SWE-bench Verified measures a model’s ability to solve real GitHub issues from popular open-source projects — not toy problems, but actual bugs and feature requests that human developers submitted. A 2-point jump here is significant because it means Claude Opus 4.1 can now resolve roughly 1 in 50 additional real-world coding tasks that its predecessor couldn’t. For teams using Claude as a coding assistant across dozens of daily tasks, that compounds quickly into measurable time savings.
Context matters here: when SWE-bench first launched, the best models were scoring below 30%. Breaking 70% was considered a milestone, and now we’re seeing two models above 74%. The rate of improvement is accelerating even as the problems get harder, because the remaining unsolved issues tend to involve multi-step reasoning across unfamiliar codebases.
Terminal-bench: 39.2% → 43.3%
This is the most dramatic percentage improvement at over 4 points. Terminal-bench tests a model’s ability to work in command-line environments — debugging, scripting, system administration tasks, and navigating complex file systems. A jump from 39.2% to 43.3% represents a roughly 10% relative improvement, which is substantial for what’s arguably the most practical coding benchmark for DevOps engineers and backend developers who live in the terminal.
The Terminal-bench improvement also correlates directly with Claude Code’s effectiveness. If you’re using Claude Code for terminal-based development workflows — git operations, Docker management, CI/CD debugging — this is where you’ll feel the biggest day-to-day difference.
GPQA (Science): 79.6% → 80.9%
Graduate-level science reasoning saw a modest but steady gain. At these high levels, every percentage point becomes exponentially harder to earn. GPQA questions are designed to stump non-expert PhDs, so breaking the 80% barrier consistently demonstrates genuinely robust scientific reasoning capability.
AIME (Math): 75.5% → 78.0%
A 2.5-point gain on competition-level mathematics. This improvement in mathematical reasoning often correlates with better logical deduction in code — the same neural pathways that solve math competition problems help with complex algorithmic challenges, recursive logic, and optimization problems that show up in everyday software engineering.
Other Benchmarks: A Mixed Bag
Multilingual QA improved slightly from 88.8% to 89.5%, and visual reasoning nudged from 76.5% to 77.1%. TAU-bench retail saw a small gain from 81.4% to 82.4%. These are incremental but show that Anthropic’s improvements didn’t come at the cost of regression in other areas — with one notable exception.
Where It Didn’t Improve: TAU-bench Airline
Not everything went up. TAU-bench airline actually declined from 59.6% to 56.0%. These benchmarks measure agentic task completion in simulated customer service environments, and the airline regression is worth noting for anyone deploying Claude in customer-facing roles. The decline suggests Anthropic’s optimization focus was squarely on coding and reasoning tasks where commercial demand is highest. If your primary use case is customer service automation, this trade-off deserves careful evaluation before upgrading.
The Real Upgrades: What Developers Will Actually Feel
Benchmark numbers tell part of the story. The practical improvements in daily workflows tell the rest. According to Anthropic’s announcement and independent analysis from developers who’ve been testing since launch day, Claude Opus 4.1 brings several targeted enhancements that address the most common frustrations with AI coding assistants:
- Multi-file code refactoring — The model now handles cross-file dependencies more reliably. If you’re asking Claude to rename a function and update all its call sites across a codebase, Opus 4.1 tracks those connections better than its predecessor. This was one of the most requested improvements, as broken cross-file refactors were a leading cause of wasted developer time.
- Enhanced debugging precision — Fewer false positives when diagnosing bugs. The model is better at distinguishing between symptoms and root causes, particularly in stack traces that span multiple layers of abstraction. Instead of suggesting surface-level fixes, Opus 4.1 more reliably traces issues to their origin.
- Better detail tracking in long sessions — With extended thinking now supporting up to 64K tokens, the model can maintain context over much longer reasoning chains. This is critical for complex architectural decisions where you need the model to hold multiple constraints in mind simultaneously without forgetting requirements mentioned earlier.
- Reduced hallucination during extended reasoning — Longer thinking doesn’t mean more fabrication. Anthropic specifically targeted the failure mode where models “fill in” plausible but incorrect details during extended reasoning chains. This is a subtle but crucial improvement — a model that confidently produces wrong code is worse than one that admits uncertainty.
- Simplified tool architecture — Under the hood, how the model interacts with external tools has been streamlined. For developers building agentic workflows that chain multiple API calls, database queries, and file operations, this means more predictable and reliable tool-use patterns with fewer dropped or malformed tool calls.
- One standard deviation improvement on junior developer benchmarks — A useful practical proxy: tasks that a typical junior developer would handle (CRUD operations, API integrations, test writing, data transformations) got measurably easier for the model. This matters because these tasks represent the bulk of AI-assisted coding in enterprise environments.
The Competitive Context: GPT-5 and the SWE-bench Race
Here’s where the story gets truly interesting. OpenAI’s GPT-5, also released in August 2025, scored 74.9% on SWE-bench Verified — just 0.4 percentage points ahead of Claude Opus 4.1’s 74.5%. We’re officially in a tight race where the margin between the top models is smaller than the benchmark’s own statistical variance.
What does this mean practically? If you’re choosing between these models purely on coding ability, the numerical difference is negligible. One run of SWE-bench could easily flip the ranking. The real differentiators become pricing, ecosystem integration, context window handling, and how each model feels to work with day-to-day. Claude’s 200K context window and extended thinking up to 64K tokens remain competitive advantages for long-form code analysis tasks, while GPT-5 may have edges in other areas depending on your specific workflow.
The broader implication is more significant: we’ve entered an era where the top-tier coding AI models are functionally equivalent on standardized benchmarks. The competition is now shifting from raw capability to reliability, developer experience, and ecosystem maturity. That’s good news for developers — it means the floor keeps rising regardless of which provider you choose.

Extended Thinking: 64K Tokens of Reasoning Space
The extended thinking upgrade to 64K tokens deserves its own section because it fundamentally changes how Claude Opus 4.1 handles complex problems. When you enable extended thinking, the model doesn’t just produce a longer chain-of-thought — it produces a more structured one. In practice, this means the model can now:
- Plan multi-step refactoring operations before executing them, reducing the chance of half-completed changes
- Evaluate trade-offs between different architectural approaches more thoroughly before committing to a direction
- Catch edge cases that shorter reasoning chains would miss, particularly in concurrent and distributed systems
- Maintain accuracy over longer debugging sessions where the root cause isn’t immediately obvious and requires exploring multiple hypotheses
For developers using Claude Code or the API with agentic workflows, 64K tokens of extended thinking is the difference between a model that rushes through a problem and one that actually thinks it through. Consider a scenario where you ask Claude to refactor a payment processing module that touches 15 files — with 64K thinking tokens, the model can map out all the dependencies, plan the order of changes, and execute them coherently. With shorter thinking chains, it would start changing files and lose track of which interfaces need updating.
Pair this with the reduced hallucination during extended reasoning, and you get a model that’s not just thinking longer — it’s thinking better. The quality per token of reasoning has improved alongside the quantity.
Availability and Integration: Where to Access Claude Opus 4.1
Anthropic made Opus 4.1 available across all existing channels simultaneously, which is a departure from the staggered rollouts we’ve seen with some competitor releases. Here’s the full availability picture:
- Anthropic API — Direct access via the API using the model ID
claude-opus-4-1-20250805. Drop-in replacement for existing Opus 4 integrations. - Claude.ai — Available immediately to Pro and Team subscribers. No configuration needed.
- Claude Code — The CLI tool automatically picks up the new model. Developers using Claude Code for terminal workflows will notice the Terminal-bench improvements here first.
- Amazon Bedrock — Enterprise teams on AWS can access Opus 4.1 through Bedrock with the same SLAs and compliance certifications as Opus 4.
- Google Vertex AI — Available for teams in the Google Cloud ecosystem, maintaining multi-cloud deployment flexibility.
The simultaneous availability across all platforms is worth noting because it eliminates the “which platform gets it first” guessing game that creates friction for enterprise procurement teams. If you’re on any of these platforms, you can start testing today.
Who Should Upgrade (and Who Shouldn’t)
Since pricing is identical to Opus 4, the upgrade question is straightforward for most users. But there are nuances worth considering:
Upgrade immediately if you:
- Use Claude for multi-file code generation or large-scale refactoring projects
- Build agentic AI workflows that chain multiple tool calls in sequence
- Need extended reasoning for complex architectural decisions or system design
- Work with large codebases where context tracking across files matters
- Run Claude Code as part of your daily terminal development workflow
Stay on Opus 4 or consider alternatives if you:
- Primarily use Claude for customer-facing conversational tasks (the TAU-bench airline decline is a flag worth investigating)
- Are cost-sensitive and could use Sonnet 4 for most tasks — Opus pricing at $15/$75 per million tokens is steep if you don’t need flagship performance
- Need deterministic outputs for compliance or testing purposes — any model upgrade can change behavior in subtle ways that break brittle test suites
The Bigger Picture: Iterative Refinement Over Generational Leaps
Claude Opus 4.1 signals a shift in how frontier AI labs ship improvements. Instead of waiting for a dramatic generational jump that might break existing integrations, Anthropic is opting for frequent, targeted refinements. This is a mature engineering approach — the kind you see in established software platforms, not moonshot research labs.
For enterprise teams building on these models, this is genuinely good news. Predictable, incremental improvements are far easier to plan around than disruptive leaps that might break existing workflows. You can adopt Opus 4.1 with confidence that your existing prompts, system integrations, and evaluation pipelines will work — just slightly better than before. No emergency refactoring of your AI infrastructure required.
The question for the rest of 2025 isn’t whether Claude Opus 4.1 is “better” — it objectively is across most benchmarks. The question is whether this iterative approach can keep pace with competitors who might be preparing bigger moves. With GPT-5 already matching Anthropic on SWE-bench, the next major update from either side could shift the landscape significantly. For now, Claude Opus 4.1 represents the state of the art in AI-assisted coding — tied at the top with GPT-5, and pulling ahead on extended reasoning and agentic task completion. If you’re building production systems with AI, this is the model to test against.
Building AI-powered workflows or integrating models like Claude Opus 4.1 into your development pipeline? Let’s talk about what architecture fits your needs.
Get weekly AI, music, and tech trends delivered to your inbox.



{kind=link}
{kind=link}
{kind=link}