UJAM Groovemate Latigo Review: 460 Latin Percussion Phrases From an Ex-Jamiroquai Musician — Is It Worth $39?
April 3, 2026
GitHub Copilot Data Training Starts April 24: 7 Reasons to Opt Out Now Before Your Private Code Feeds AI Models
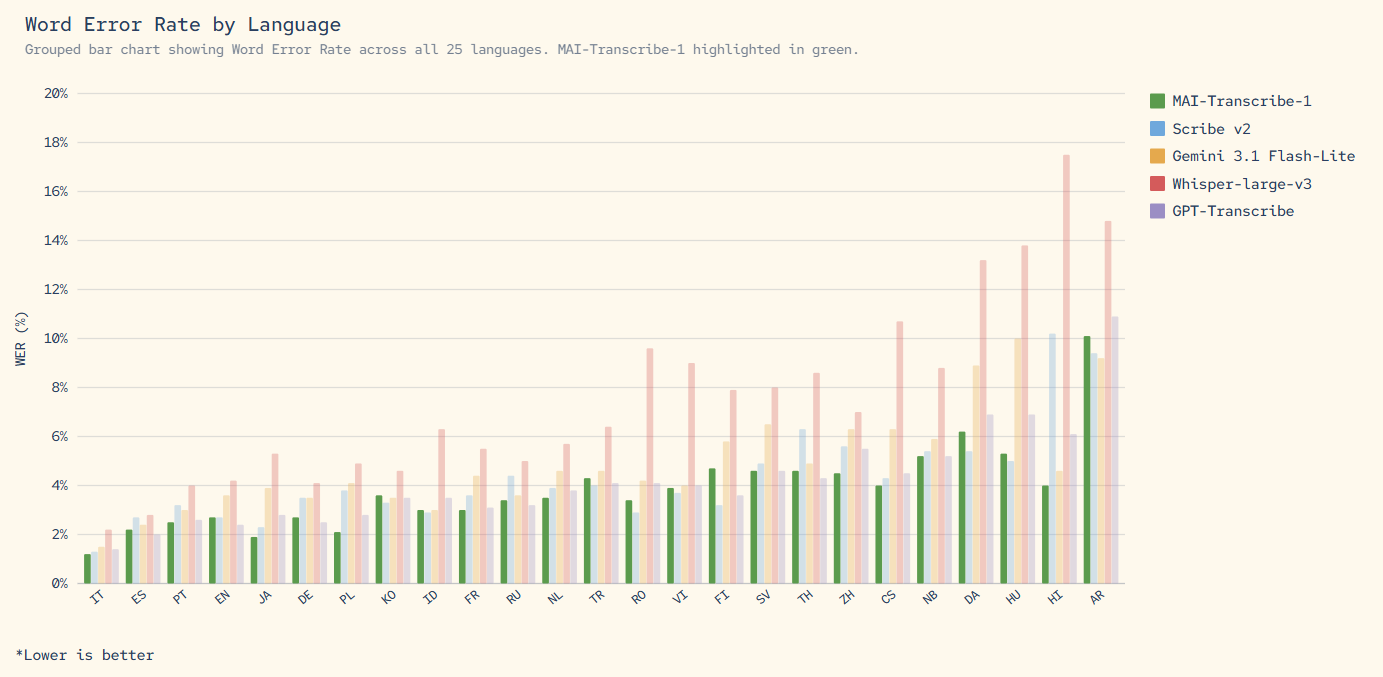
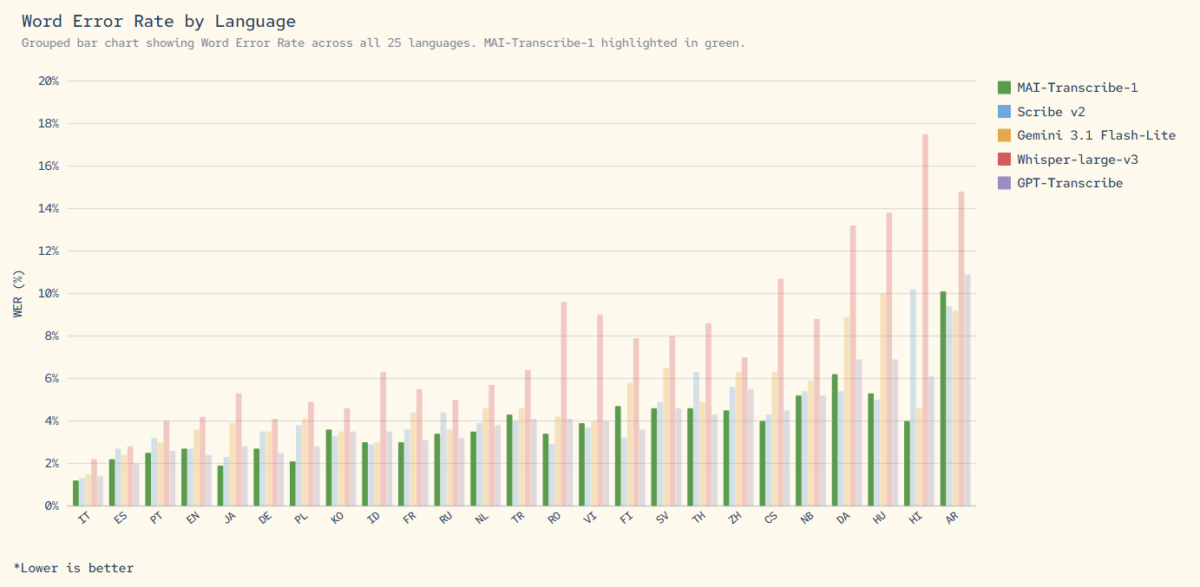
April 3, 2026If you still think OpenAI’s Whisper is the undisputed king of speech recognition, yesterday changed everything. On April 2, 2026, Microsoft dropped three in-house foundation models simultaneously — and the headliner, MAI-Transcribe-1, beat Whisper-large-v3 on every single one of the 25 languages in the FLEURS benchmark. Every. Single. One.

Why Microsoft MAI Models Matter Right Now
This isn’t just another product launch. This is Microsoft declaring that it’s building its own foundation model stack — while still being OpenAI’s biggest investor. As VentureBeat reported, the triple launch is a “direct shot at OpenAI and Google.” The strategic implications are massive.
TechCrunch frames it as Microsoft’s play to reduce OpenAI dependency — building self-sufficient capabilities across speech, voice, and image generation. All three models are available immediately through Azure AI Foundry and the MAI Playground.
The timing is no accident. Google has been aggressively expanding its multimodal AI capabilities with the Gemini 3.1 series, and OpenAI is building toward GPT-5. By launching proprietary models across speech and image domains now, Microsoft is ensuring it has its own weapons in the platform war — regardless of how its OpenAI partnership evolves. For Azure customers, this means they can now compare and choose between OpenAI APIs and Microsoft’s own MAI models within the same infrastructure, creating genuine competitive pressure that benefits end users.
MAI-Transcribe-1: 3.8% WER That Beats Everything
The star of the show is undeniably MAI-Transcribe-1. It posted a 3.8% average Word Error Rate across 25 languages on the FLEURS benchmark, claiming the #1 spot in 11 core languages. That’s not just better than OpenAI’s Whisper-large-v3 — it also beats Google’s Gemini 3.1 Flash and GPT-Transcribe.
But the performance numbers are only half the story. According to Microsoft’s official announcement, MAI-Transcribe-1 runs 2.5x faster than its Azure Fast predecessor while cutting GPU costs by roughly 50%. The pricing? $0.36 per hour of audio, supporting MP3, WAV, and FLAC files up to 200MB.
To put this in direct competitive context: Whisper-large-v3 has long been the go-to open-source transcription model, but it has well-documented weaknesses. Its error rates climb significantly on non-Latin script languages — Korean, Japanese, Arabic, and Hindi transcriptions have historically been noticeably less accurate than English. MAI-Transcribe-1 appears to have targeted exactly these pain points, delivering consistent accuracy across all 25 benchmarked languages including those non-Latin script ones. Google’s Gemini 3.1 Flash offers transcription as part of its general-purpose multimodal toolkit, but as a dedicated model, MAI-Transcribe-1 has the edge in both accuracy and processing speed for pure transcription workloads.
The real-world applications where this model shines brightest are substantial. Global media companies handling multilingual content subtitling at scale will see immediate benefits. Call centers processing thousands of hours of customer conversations across different languages can now automate transcription with higher confidence. Universities and online education platforms generating lecture captions — particularly for international programs with diverse language needs — get a more reliable pipeline. Legal and medical professionals who need accurate meeting transcripts in multiple languages now have a tool that doesn’t degrade on non-English content. And for multilingual podcasts or international conferences where multiple languages appear in a single recording, the consistent cross-language accuracy is a genuine breakthrough.
MAI-Voice-1: 60 Seconds of Audio in Under 1 Second
The text-to-speech market has been dominated by ElevenLabs and Resemble AI, but MAI-Voice-1 arrives with numbers that demand attention. It generates 60 seconds of high-fidelity audio in under 1 second on a single GPU. It also includes voice cloning from just a few seconds of sample audio — creating custom voices that maintain speaker identity across long-form content.
Pricing comes in at $22 per million characters. The key differentiator is consistency — maintaining the cloned voice’s identity and quality across extended content. For audiobook production, e-learning platforms, and podcast workflows, this could be a genuine game-changer.
How does MAI-Voice-1 actually stack up against the incumbents? ElevenLabs has built its reputation on emotional expressiveness and a vast voice library — their voices can convey subtle emotional nuances that feel remarkably human. Resemble AI has carved out a niche in real-time voice conversion and offers strong API flexibility. MAI-Voice-1’s competitive advantage is pure speed and cost efficiency. Generating 60 seconds of audio in under one second is an order of magnitude faster than most competitors, and at $22 per million characters, it undercuts ElevenLabs’ enterprise pricing (typically $24–$30 per million characters). For enterprise customers already embedded in the Microsoft ecosystem, the zero-friction integration with Azure services eliminates the overhead of managing separate API credentials, billing, and data pipelines.
The use cases that immediately come to mind are compelling. Global e-learning platforms localizing a single course into 20+ languages can now generate voice content at a fraction of the time and cost. News organizations pursuing audio-first strategies can automatically convert written articles into spoken news briefings. Game developers generating NPC dialogue at scale — think thousands of unique voice lines — can leverage the speed to iterate rapidly during development. Accessibility teams converting web content to audio for visually impaired users get a tool that’s both fast and affordable. And corporate training departments producing multilingual onboarding content can maintain a consistent brand voice across every language version.
MAI-Image-2: Gunning for DALL-E and Imagen
MAI-Image-2 is Microsoft’s text-to-image entry, currently sitting at #3 on the Arena.ai leaderboard by model family. It’s at least 2x faster than the previous generation, with pricing at $5 per million input tokens and $33 per million output tokens.
The real play here isn’t just competing with OpenAI’s DALL-E or Google’s Imagen on quality. It’s platform consolidation. With MAI-Transcribe-1, MAI-Voice-1, and MAI-Image-2 all living inside the Microsoft Foundry ecosystem, enterprises can now handle speech recognition, voice generation, and image creation without leaving the Azure stack.
In the current image generation landscape, DALL-E 3 leads in text rendering fidelity and prompt adherence — it’s remarkably good at putting the right words in the right places within generated images. Google’s Imagen 3 excels at photorealism and fine detail, producing images that can be difficult to distinguish from photographs. Midjourney continues to dominate artistic and stylistic image generation, with an aesthetic quality that creative professionals gravitate toward. MAI-Image-2 landing at #3 on Arena.ai means its general-purpose image quality is already in the top tier. But the real competitive moat isn’t individual image quality — it’s ecosystem integration. When you can build an end-to-end content pipeline that generates text, creates images, and synthesizes voice all within a single platform, the efficiency gains for automated content production become exponential. Marketing teams, content agencies, and media companies that already run on Azure can add image generation to their existing workflows without any new infrastructure.
The Pricing Breakdown: Where Microsoft MAI Models Stand
Let’s cut to what matters most — cost. Here’s where Microsoft’s pricing lands:
- MAI-Transcribe-1: $0.36/hour — approximately 50% lower GPU cost than competitors
- MAI-Voice-1: $22 per million characters — competitive with ElevenLabs enterprise tiers
- MAI-Image-2: $5/1M input tokens, $33/1M output tokens
The transcription pricing is particularly aggressive. For media companies or education platforms processing massive volumes of audio, a 50% GPU cost reduction translates to tens of thousands of dollars saved annually. As one analysis noted, the $0.36 per audio hour rate combined with the speed improvement makes this one of the most cost-effective transcription solutions on the market.
Let’s do some concrete math. Imagine a media company transcribing 100 hours of audio per day. At MAI-Transcribe-1’s rate of $0.36/hour, that’s $36/day or roughly $1,080/month. Compared to running a GPU-based Whisper pipeline — which typically costs around $0.70–$0.75/hour when you factor in compute, storage, and maintenance — the savings add up to approximately $13,000 per year. Factor in the 2.5x speed improvement, which means shorter processing queues and lower infrastructure overhead, and the real-world savings are even more significant. For MAI-Voice-1, the $22 per million characters sits comfortably below ElevenLabs’ enterprise tier of $24–$30 per million characters, while offering faster generation speeds. The MAI-Image-2 pricing is harder to compare directly since different image models use different billing units, but within the Azure ecosystem the token-based pricing integrates cleanly with existing billing structures.
The Microsoft-OpenAI Tension: What’s Really Going On
The elephant in the room is the relationship dynamics. Microsoft has poured billions into OpenAI, yet here it is releasing models that directly compete with Whisper, DALL-E, and potentially future OpenAI offerings. GeekWire’s coverage frames this as Microsoft “expanding further beyond OpenAI,” building insurance against over-reliance on a single AI partner.
This isn’t necessarily adversarial — it’s pragmatic. Enterprise customers want options, and Microsoft is positioning itself to offer a full stack regardless of how the OpenAI partnership evolves. But the competitive pressure is real. OpenAI can’t ignore that its biggest backer just released a model that beats Whisper on every benchmarked language. The question now is whether this pushes OpenAI to accelerate its own next-generation speech models, creating a virtuous cycle of competition that benefits everyone downstream.
My Take: What 28 Years in Audio Taught Me About This
After 28 years in the music and audio industry, I’ve watched speech recognition evolve from a frustrating novelty to a production-grade tool. Just a few years ago, multilingual transcription meant hiring specialized services or doing it by hand. Whisper changed the game. And now Microsoft MAI models are changing it again.
What catches my attention most is MAI-Voice-1’s voice cloning capability. In studio work, we constantly face the challenge of maintaining a specific vocal tone and style across large volumes of content. If a few seconds of sample audio can produce a reliable voice clone, the implications for localization, e-learning content, and even music production workflows are profound. I’m already thinking about how this could transform voiceover sessions where consistency is critical. In my own audio automation pipeline, I’m planning to benchmark MAI-Voice-1 against ElevenLabs to see whether the speed advantage holds up in production conditions with Korean and English content.
On the transcription side, I want to add a practical note. I currently run automated systems that process audio content in multiple languages, and Whisper’s error rate on Korean and Japanese has been noticeably higher than on English in my real-world usage. If MAI-Transcribe-1 delivers the consistent cross-language accuracy that the FLEURS benchmarks suggest, it would eliminate one of the most persistent bottlenecks in multilingual content workflows. The gap between benchmark numbers and production reality is something I always verify firsthand, so testing MAI-Transcribe-1 against my existing pipeline with real Korean audio data is the next step on my list.
But let’s be honest about the bigger picture. Microsoft investing billions in OpenAI while shipping competing models creates a fascinating tension. The Whisper users who migrate to MAI-Transcribe-1 won’t look back if the benchmarks hold up in real-world conditions — and OpenAI won’t sit still. The real winner in the voice AI market will probably be decided by the end of this year. What matters most right now is that this competition is driving costs down and quality up across the board. Whether you end up using MAI-Transcribe-1, an improved Whisper v4, or Google’s next Gemini iteration, every option is going to be better and cheaper because of this competitive pressure.
The MAI model launch signals a fundamental shift in AI industry dynamics. Microsoft is no longer content to just invest in others — it’s competing head-on across speech recognition, voice generation, and image creation. For developers and creators, this means more choices and lower costs. If you work with audio in any capacity, MAI-Transcribe-1 and MAI-Voice-1 deserve a spot on your testing list immediately.
Interested in building AI-powered audio pipelines or automation systems? Let’s talk — 28 years of industry experience at your disposal.
Get weekly AI, music, and tech trends delivered to your inbox.



{kind=link}
{kind=link}
{kind=link}
{kind=link}