
로지텍 G Pro X 60 Lightspeed 리뷰: KEYCONTROL이 바꾸는 5가지와 바꾸지 못하는 3가지
5월 26, 2025
Kemper Profiler MK 2: 20개 이펙트 블록, USB 오디오, 경량 스테이지 — 무엇이 달라졌는가
5월 27, 2025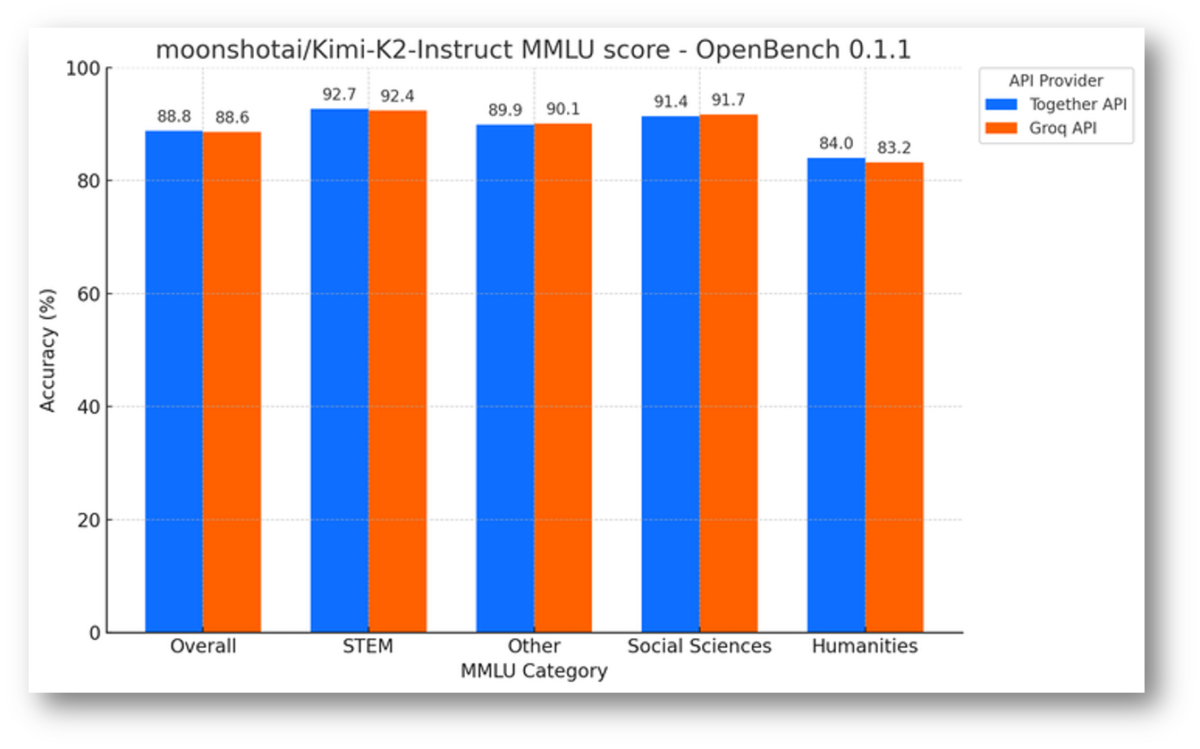
초당 625 토큰. 오타가 아닙니다. 이름 없는 연구실의 합성 벤치마크도 아닙니다. Meta의 Llama 모델을 프로덕션 환경에서 돌리는 Groq LPU 추론 엔진의 실제 수치입니다. NVIDIA의 최신 H100 GPU 클러스터보다 10배에서 18배 빠른 속도. 대형 언어모델의 응답을 3초, 5초, 10초씩 기다려본 경험이 있다면, 그 대기 시간이 곧 다이얼업 인터넷 시절의 추억이 될 수 있습니다.
매일 AI 자동화 파이프라인을 구축하는 기술 CEO로서, Groq의 행보를 첫 공개 벤치마크 때부터 주시해왔습니다. 속도 수치 자체도 인상적이지만, 진짜 중요한 것은 이 속도가 무엇을 가능하게 하는가입니다. 실시간 AI 대화, 즉각적인 코드 생성, 눈 깜짝하기 전에 응답하는 음성 비서. 엔터프라이즈 애플리케이션에 미치는 영향은 막대하며, 업계가 본격적으로 주목하기 시작했습니다.
Groq LPU 추론이란 무엇이며, 왜 중요한가
Groq의 LPU(Language Processing Unit)는 AI 추론에 대한 근본적으로 다른 접근 방식입니다. NVIDIA GPU가 원래 그래픽 렌더링용으로 설계된 후 AI 워크로드에 적응한 것과 달리, Groq은 LPU를 처음부터 순차적 텍스트 생성에 특화하여 설계했습니다. 오늘날 여러분이 사용하는 모든 챗봇, 코드 어시스턴트, AI 에이전트를 구동하는 바로 그 연산입니다.
아키텍처 차이는 본질적입니다. GPU는 외부 HBM(High Bandwidth Memory), 캐시, 분기 예측기에 의존하며, 이 모든 요소가 변동성과 지연을 발생시킵니다. 반면 LPU는 대용량 온다이 SRAM 메모리를 활용한 결정론적 실행 방식을 채택합니다. 모든 명령어가 고정된 클럭 사이클로 처리됩니다. 추측도, 캐시 미스도, 예측 불가능한 지연도 없습니다. 결과적으로 서브 밀리초 지연시간과 GPU 기반 추론을 압도하는 처리량을 달성합니다.
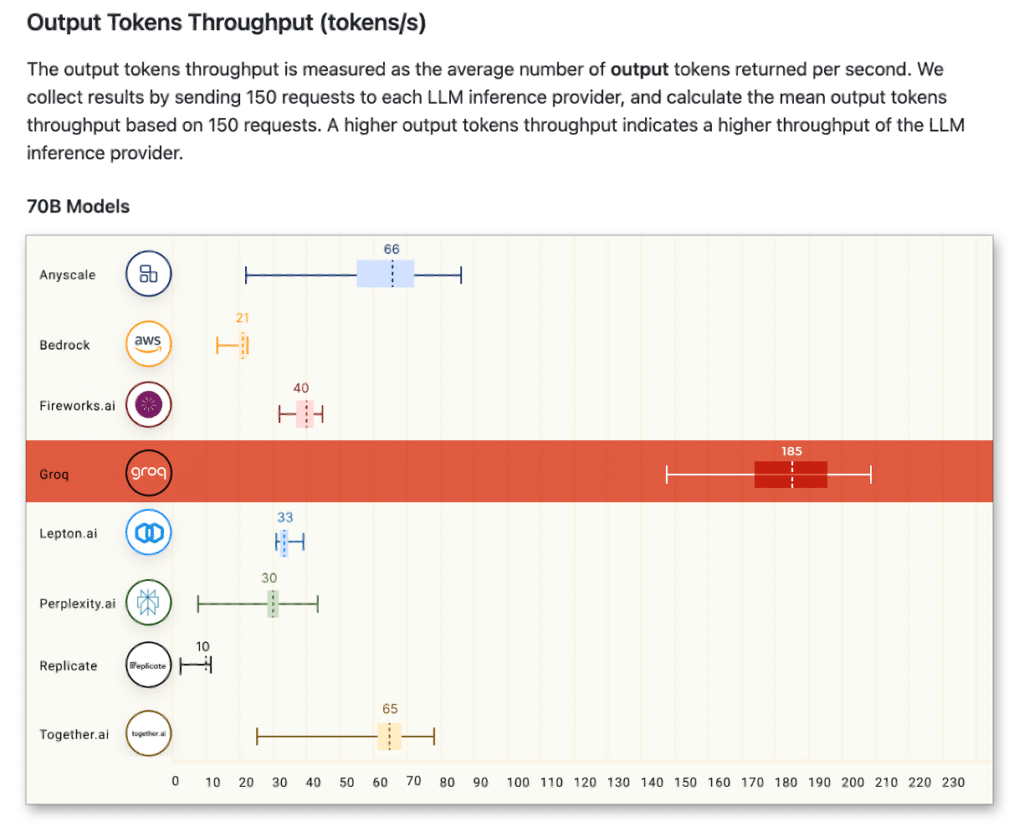
숫자로 보는 Groq LPU 추론 벤치마크
2024년 초, Groq이 ArtificialAnalysis.ai 벤치마크에 처음 등장했을 때 결과는 충격적이었습니다. 700억 파라미터 규모의 Llama 2 70B 모델에서 초당 241 토큰을 달성했습니다. 당시 어떤 클라우드 추론 서비스보다 2배 이상 빠른 수치였으며, 모델 크기에 따라 3배에서 18배까지 빠른 처리량을 기록했습니다.
2025년 중반 현재, 수치는 더욱 향상되었습니다.
- Llama 2 7B: 최대 초당 750 토큰
- Llama 3 70B: 초당 300+ 토큰
- Meta 파트너십 기반 최신 Llama 모델: 최대 초당 625 토큰
- 첫 토큰 생성 시간: GPU 기반 대안 대비 현저히 낮음
맥락을 잡아보겠습니다. 대부분의 GPU 기반 추론 서비스는 동급 모델에서 초당 30~60 토큰을 제공합니다. Groq은 근소한 차이가 아니라 차원이 다른 속도를 보여주고 있습니다. AI 애플리케이션에서 속도는 단순한 편의가 아닙니다. 사용 가능한 제품과 답답한 제품의 차이를 만드는 핵심 요소입니다.
Meta 파트너십: 모든 것을 검증하는 선택
2025년 4월 29일, Meta가 AI 업계 전체에 명확한 신호를 보냈습니다. LlamaCon에서 공식 Llama API의 인프라 파트너로 Groq을 선택한 것입니다. AWS도, Google Cloud도, NVIDIA의 자체 추론 플랫폼도 아닌 Groq을 택했습니다.
이 파트너십은 단순한 비즈니스 계약이 아닙니다. Llama 모델을 만든 당사자인 Meta가 자사 모델의 최상의 개발자 경험을 위해 Groq의 LPU 인프라를 선택한 기술적 검증입니다. Meta와 Groq의 공동 발표에 따르면, 개발자들은 단 세 줄의 코드 변경만으로 Llama API로 마이그레이션할 수 있으며, 콜드 스타트도, GPU 설정도, 성능 튜닝도 필요 없습니다.
TechRepublic은 이 파트너십이 LPU를 “세계에서 가장 효율적인 추론 칩”으로 자리매김시키며, 범용 GPU보다 전용 추론 하드웨어에 대한 업계 전반의 검증 신호라고 보도했습니다. 세계 최대 오픈소스 AI 모델 제공업체가 NVIDIA 대신 여러분의 칩을 고른다면, 그것은 마케팅 주장이 아니라 시장의 변화입니다.
LPU vs GPU: Groq LPU 추론의 아키텍처가 중요한 이유
GPU vs LPU 논쟁은 어떤 칩이 절대적으로 “더 좋은가”의 문제가 아닙니다. 각 칩이 무엇을 위해 설계되었는가의 문제입니다. GPU는 병렬 처리의 강자입니다. 대규모 데이터 배치를 동시에 처리해야 하는 AI 모델 훈련에 탁월합니다. 그러나 추론 — 한 번에 하나의 토큰을 순차적으로 생성하는 작업 — 은 본질적으로 다른 워크로드입니다.
비유하자면, GPU는 1만 차선의 대형 고속도로입니다. 대량의 교통량을 한꺼번에 이동시키는 데는 최적입니다. 하지만 한 대의 차량이 A 지점에서 B 지점까지 가능한 한 빨리 도달해야 한다면, 나머지 차선들은 무용지물입니다. LPU는 신호등도, 교차로도, 지연도 없는 완벽하게 최적화된 단일 트랙에 가깝습니다. 차 한 대, 최대 속도.
기술적 세부사항이 핵심입니다. LPU는 GPU 추론을 괴롭히는 메모리 대역폭 병목을 제거합니다. 외부 HBM 대신 온다이 SRAM을 사용하므로 데이터가 버스를 통해 처리 유닛으로 이동할 필요가 없습니다. Groq은 추론 워크로드에서 GPU 대비 5배 이상 우수한 에너지 효율을 달성한다고 밝혔습니다. 하루 수백만 건의 API 호출을 처리하며 대규모로 추론을 실행할 때, 이 효율성 차이는 결정적입니다.
GroqCloud 개발자 생태계: 190만 명을 넘어서
아무리 빨라도 접근성이 없으면 의미가 없습니다. Groq은 이를 잘 알고 있으며, 현재 190만 명 이상의 개발자가 사용하는 GroqCloud 플랫폼을 구축했습니다. API가 OpenAI 호환이므로, 기존 애플리케이션은 최소한의 코드 변경만으로 Groq 인프라로 전환할 수 있습니다. GPU 기반 클라우드 서비스에 묶여 있던 개발자들에게 매력적인 대안입니다.
펀딩이 수요를 말해줍니다. 2024년 8월, Groq은 28억 달러 밸류에이션으로 6억 4천만 달러 규모의 시리즈 D 라운드를 마감했으며, 2025년 초까지 10만 개 이상의 LPU를 클라우드에 배치할 계획을 발표했습니다. 이미 Dropbox(문서 지능화), Volkswagen(차량 내 AI 비서), Riot Games(실시간 플레이어 지원) 등 엔터프라이즈 고객이 프로덕션에서 활용 중입니다. 실험이 아니라 추론 속도가 사용자 경험에 직접 영향을 미치는 실전 배포입니다.
사우디아라비아의 15억 달러 투자 보도도 주목할 만합니다. 국가 단위 AI 인프라가 글로벌 우선순위가 되는 상황에서, Groq의 LPU가 속도와 에너지 효율을 모두 요구하는 AI 배포의 추론 백본으로 자리잡고 있다는 신호입니다.
NVIDIA 독점에 대한 현실적 질문
서버실의 코끼리에 대해 솔직해져야 합니다. NVIDIA는 AI 칩 시장의 약 80~90%를 장악하고 있습니다. CUDA 생태계는 깊이 뿌리내리고 있으며, 수천 개의 AI 기업이 NVIDIA GPU 위에 전체 인프라를 구축했습니다. Groq이 NVIDIA를 하룻밤 만에 대체하지는 않을 것입니다.
하지만 핵심은 거기가 아닙니다. AI 컴퓨트 시장은 훈련과 추론이라는 두 가지 뚜렷한 워크로드로 분화하고 있습니다. NVIDIA는 훈련을 지배하고 있으며, 이는 쉽게 바뀌지 않을 것입니다. 그러나 추론 — 모든 AI 애플리케이션의 매출을 만들어내는 워크로드 — 은 다른 게임입니다. AI가 연구실에서 프로덕션 애플리케이션으로 이동하면서, 추론 컴퓨트는 훈련 컴퓨트보다 기하급수적으로 빠르게 성장하고 있습니다. 일부 분석가들은 향후 2~3년 내에 추론이 전체 AI 컴퓨트 지출의 70~80%를 차지할 것으로 전망합니다.
Groq의 전략적 베팅이 합리적인 이유가 여기에 있습니다. NVIDIA를 전 분야에서 이길 필요는 없습니다. 추론 레이어만 장악하면 됩니다. 해당 워크로드에서 10배 빠르고 5배 에너지 효율적인 칩이 있다면, 경제성은 스스로 말해줄 것입니다. SemiAnalysis의 분석처럼 Groq의 속도 우위가 인프라 투자를 정당화할 수 있는지라는 비용 문제가 남아 있지만, Meta 파트너십은 시장이 긍정적으로 답하기 시작했음을 시사합니다.
실시간 AI 애플리케이션에 미치는 의미
AI 자동화 시스템을 구축하는 입장에서, Groq LPU 추론의 가장 흥미로운 함의는 원시 속도 자체가 아니라 그 속도가 가능하게 하는 것들입니다. 초당 500 토큰 이상이면 AI 응답은 순간적으로 느껴집니다. 이는 AI 애플리케이션의 설계 패러다임 자체를 바꿉니다.
실시간 음성 AI를 생각해보십시오. 현재 GPU 기반 추론은 대화 중 어색한 공백을 만들 만큼의 지연을 발생시킵니다. Groq 속도에서는 AI 음성 비서가 사람만큼 자연스럽게 응답할 수 있습니다. 실시간 코드 생성이 진정한 의미에서 인터랙티브해지며, 고객 지원 봇이 벽에 말하는 듯한 느낌에서 자연스러운 대화로 전환됩니다.
Volkswagen이나 Dropbox 같은 엔터프라이즈 고객에게 이것은 자랑거리가 아닙니다. 제품 품질의 문제입니다. 3초 걸리는 차량 AI 비서는 짜증납니다. 200밀리초 만에 응답하는 AI 비서는 마법처럼 느껴집니다. 바로 그 격차를 Groq이 좁히고 있습니다.
업계 전반의 흐름은 명확합니다. AI 추론은 “충분히 빠른” 수준에서 “실시간”으로 이동하고 있으며, Groq의 LPU와 같은 전용 하드웨어가 그 전환을 이끌고 있습니다. NVIDIA가 자체 추론 최적화 아키텍처로 대응하든, Groq이 이 틈새를 계속 확장하든, 승자는 더 빠르고 반응성 높은 AI 애플리케이션을 사용하게 될 모든 개발자와 사용자입니다.
실시간 AI 추론 경쟁은 더 이상 이론이 아닙니다. Meta의 공인, GroqCloud의 190만 개발자, 이미 프로덕션에서 작동하는 엔터프라이즈 배포까지. Groq의 LPU는 “흥미로운 스타트업”에서 “정당한 업계 세력”으로 진화했습니다. 앞으로 12개월이 이것이 진정한 아키텍처 전환의 시작인지, 아니면 NVIDIA의 끊임없이 확장하는 로드맵에 흡수될 속도 우위인지를 결정할 것입니다. 어느 쪽이든, AI는 방금 훨씬 빨라졌습니다.
AI 추론 속도와 아키텍처 결정이 기술 스택에 미치는 영향이 궁금하시다면, 더 빠른 AI 시스템 구축에 대해 이야기해 보겠습니다.
매주 AI, 음악, 테크 트렌드를 이메일로 받아보세요.


{kind=link}
{kind=link}
{kind=link}