
AMD Radeon RX 9060 XT: The $299 RDNA 4 GPU That Changes Budget 1080p Gaming
June 9, 2025
iRig Pro Quattro I/O Review: 4 XLR Inputs in a Sub-1-Pound Package That Changed My Mobile Rig
June 10, 2025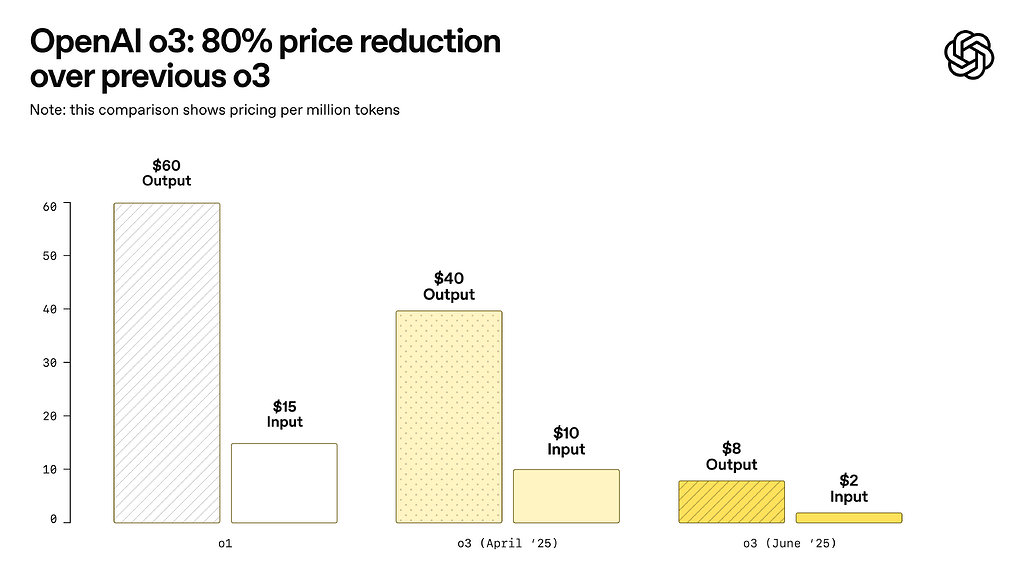
An 80% price cut overnight — no model change, no downgrade, just pure savings. On June 10, 2025, OpenAI quietly dropped one of the most significant API pricing updates of the year: the o3 reasoning model went from $10 to $2 per million input tokens, while a brand-new o3-pro tier launched at a fraction of what o1-pro used to cost.
If you’ve been budgeting around o3’s original pricing, it’s time to recalculate everything. Here’s what changed, what it means for your production workloads, and how the new OpenAI o3 price cut stacks up against competing models.
The OpenAI o3 Price Cut: From $10 to $2 Per Million Tokens
OpenAI’s announcement was refreshingly straightforward: “We optimized our inference stack that serves o3. Same exact model — just cheaper.” No fine print, no capability trade-offs.
Here’s the before-and-after breakdown:
- o3 Input (old): $10.00 per 1M tokens → (new): $2.00 per 1M tokens
- o3 Output (old): $40.00 per 1M tokens → (new): $8.00 per 1M tokens
- Cached Input: $0.50 per 1M tokens (new discount tier)
- Effective reduction: 80% across the board
For a typical reasoning-heavy workload processing 10 million input tokens and 2 million output tokens per month, the cost drops from $180 to $36. That’s $144 in monthly savings per workflow — and for teams running dozens of reasoning pipelines, the cumulative impact is massive.
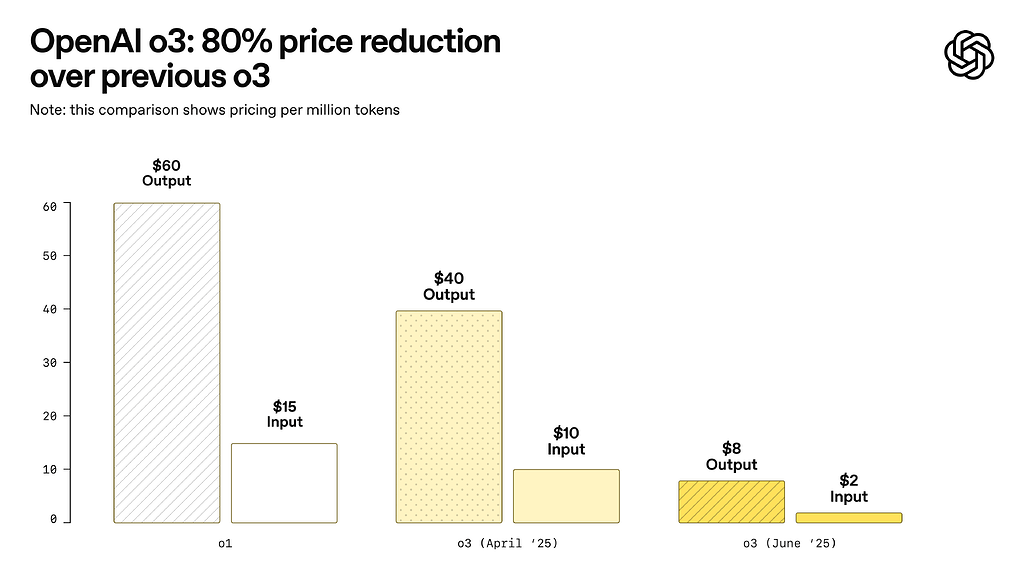
o3-pro: Enterprise-Grade Reasoning at 87% Less Than o1-pro
Alongside the o3 price cut, OpenAI launched o3-pro — a new tier that uses significantly more compute than standard o3 to “think harder” on complex problems. It’s designed for scenarios where accuracy and reliability matter more than speed.
The pricing:
- o3-pro Input: $20 per 1M tokens
- o3-pro Output: $80 per 1M tokens
- vs o1-pro: 87% cheaper for the replacement model
OpenAI recommends running o3-pro in background mode for long-running asynchronous tasks to prevent timeouts. It’s available immediately in the API and in ChatGPT’s model picker for Pro and Team subscribers.
Developer Impact: Who Benefits Most From the OpenAI o3 Price Cut?
This isn’t just a pricing announcement — it reshapes which workloads are economically viable with reasoning models. Three categories of developers stand to benefit immediately:
1. Multi-Agent Orchestration Builders
If you’re running agentic workflows where multiple AI calls chain together — code generation, analysis, validation loops — the per-call cost was previously prohibitive with o3. At $2/$8, you can now afford to let reasoning models handle intermediate steps that used to require cheaper but less capable models like GPT-4o mini ($0.15/$0.60).
2. RAG Pipeline Operators
The cached input discount at $0.50 per million tokens is a game-changer for Retrieval-Augmented Generation. If you’re feeding the same context documents repeatedly — legal contracts, codebases, knowledge bases — the effective cost per query drops dramatically. Combined with the Batch API’s additional 50% savings, high-volume RAG deployments become genuinely affordable.
3. Startups Choosing Between Reasoning and Budget
Previously, startups had to choose: use o3 for quality and blow the budget, or stick with GPT-4o mini for cost efficiency and accept lower reasoning capability. At $2/$8, o3 sits in a sweet spot — roughly 13x more expensive than GPT-4o mini, but now within reach for critical reasoning tasks while delegating routine work to cheaper models.
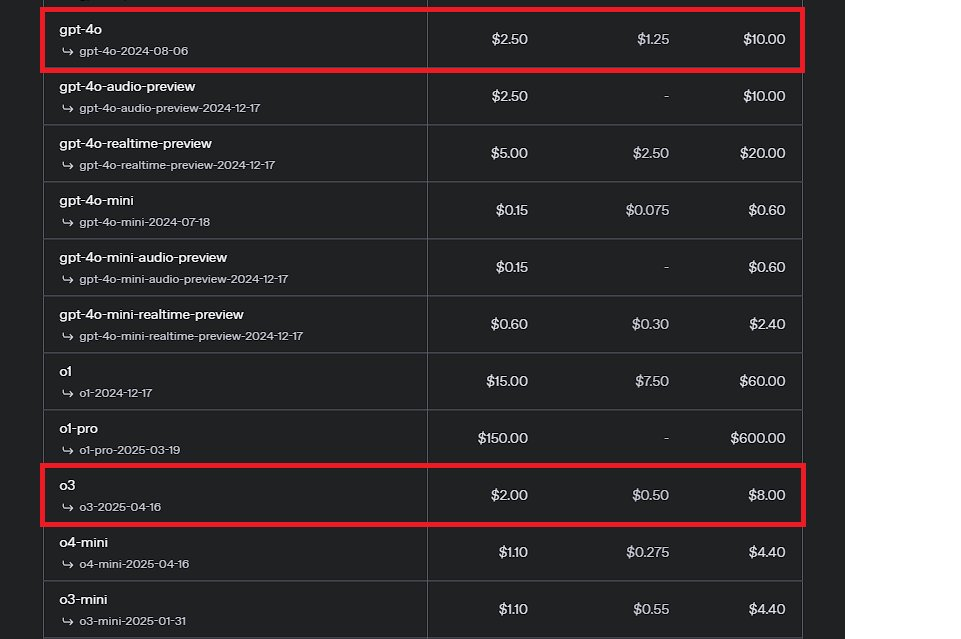
How o3’s New Pricing Compares to the Competition
As of June 2025, here’s how o3’s new pricing stacks up against other major API providers’ reasoning-capable models:
- OpenAI o3 (new): $2/$8 per 1M tokens — 80% cheaper than before
- Anthropic Claude Sonnet 4: $3/$15 per 1M tokens — o3 now undercuts on input
- Google Gemini 2.5 Pro: $1.25/$10 per 1M tokens — still cheaper on input, pricier on output
- OpenAI GPT-4o: $2.50/$10 per 1M tokens — o3 is now cheaper than GPT-4o for reasoning tasks
- DeepSeek R1: $0.55/$2.19 per 1M tokens — still the budget king for reasoning
The most striking comparison: o3 is now cheaper than GPT-4o on a per-token basis, despite being a more capable reasoning model. This pricing inversion suggests OpenAI is aggressively positioning o3 as the default choice for any task requiring multi-step thinking.
The Cached Input Strategy: Hidden Savings Most Developers Miss
Beyond the headline 80% cut, the $0.50 cached input rate deserves special attention. If your application sends identical prefixes — system prompts, few-shot examples, or shared context documents — across multiple requests, the effective input cost drops to a quarter of the already-reduced rate.
For a legal document analysis pipeline processing 100 queries against the same 50,000-token contract, the cached savings alone reduce input costs from $10 (at the old rate) to $2.75 at the new rate with caching. That’s a 72.5% additional reduction on top of the 80% price cut for repeated context.
OpenAI also confirmed that the Batch API remains available for o3 at an additional 50% discount on both cached inputs and outputs. Enterprises processing large token volumes overnight can stack these discounts for maximum savings.
What This Means for the AI Pricing Landscape
OpenAI’s move isn’t happening in a vacuum. Anthropic recently pushed Claude Sonnet 4 pricing lower, and Google continues to aggressively price Gemini 2.5 Pro. The broader trend is clear: reasoning-capable models are moving from premium tier to commodity pricing faster than anyone predicted.
For developers, this means the decision framework is shifting. The question is no longer “Can I afford reasoning models?” but “Which reasoning model gives me the best quality per dollar for my specific use case?” With o3 at $2/$8, the answer increasingly includes OpenAI’s reasoning tier for tasks that were previously cost-prohibitive.
The fact that OpenAI achieved this through inference optimization — not model compression or capability reduction — signals that further price drops are likely as they continue to optimize their serving infrastructure. If you’re building AI products in 2025, plan for a world where reasoning costs continue to fall.
Building AI products and need help optimizing API costs, selecting models, or architecting multi-agent systems? Let’s talk strategy.
Get weekly AI, music, and tech trends delivered to your inbox.


{kind=link}
{kind=link}
{kind=link}