
Intel Lunar Lake NUC Mini PC Review: Compact Desktop for Home and Office
August 6, 2025
GarageBand AI Drummer Gets Smarter in August 2025 iOS Update — Spatial Audio Arrives for Mobile Producers
August 7, 2025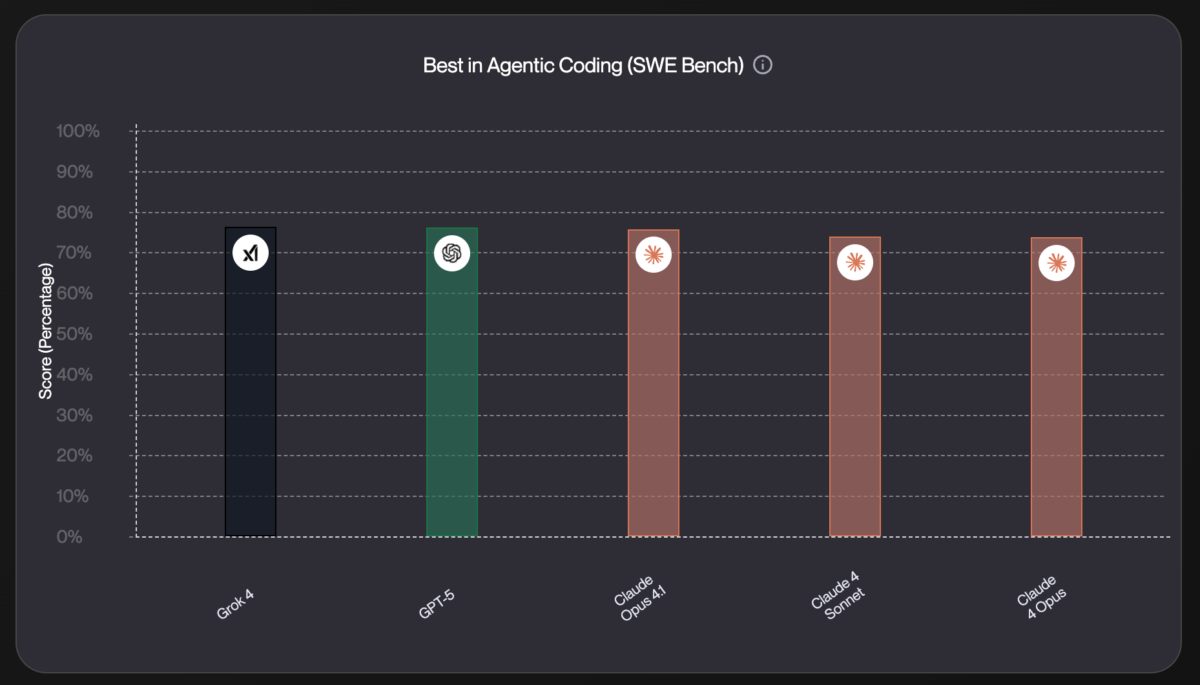
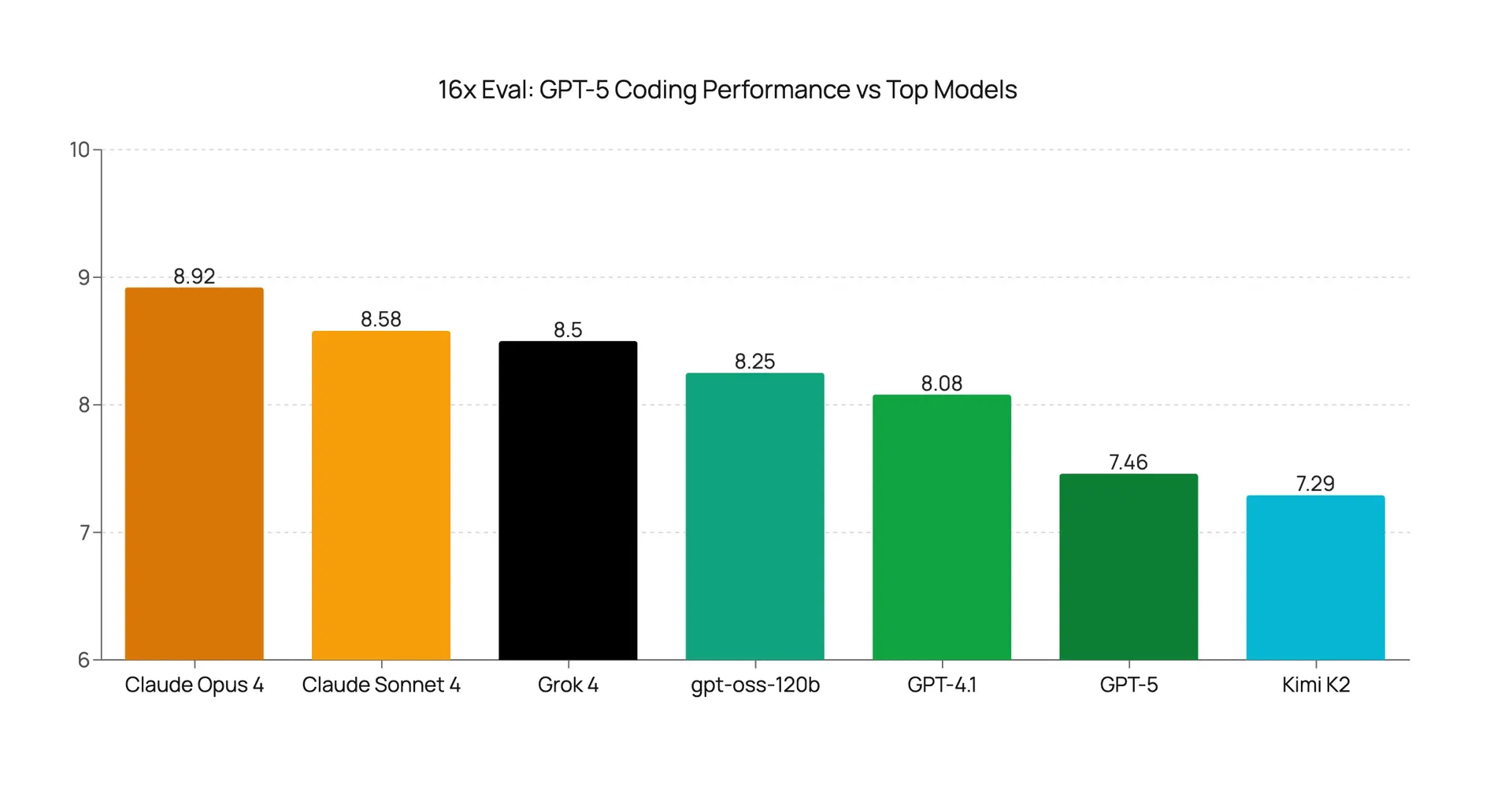
SWE-Bench Verified 74.9%. Aider Polyglot 88%. Multi-file refactoring 91%. Looking at GPT-5’s coding benchmarks alone, you’d think OpenAI just cracked the code on AI-assisted development. But here’s what nobody’s talking about yet: an independent evaluation by 16x Engineer rated GPT-5’s real-world GPT-5 SWE-Bench coding performance at just 7.46 out of 10 — well behind Claude Opus 4’s 8.92. The gap between benchmarks and your actual development experience might be wider than you think.
GPT-5 SWE-Bench Coding Performance: The Numbers That Turned Heads
OpenAI launched GPT-5 today, August 7, 2025, through its LIVE5TREAM event. The specification sheet alone is genuinely impressive: a 400K context window split between 272K input and 128K output tokens, API pricing at $1.25 per million input tokens and $10 per million output tokens, and 80% fewer factual errors compared to previous generations. The hallucination rate drops below 1% on open-source prompts, which is a meaningful improvement for production applications where reliability matters.
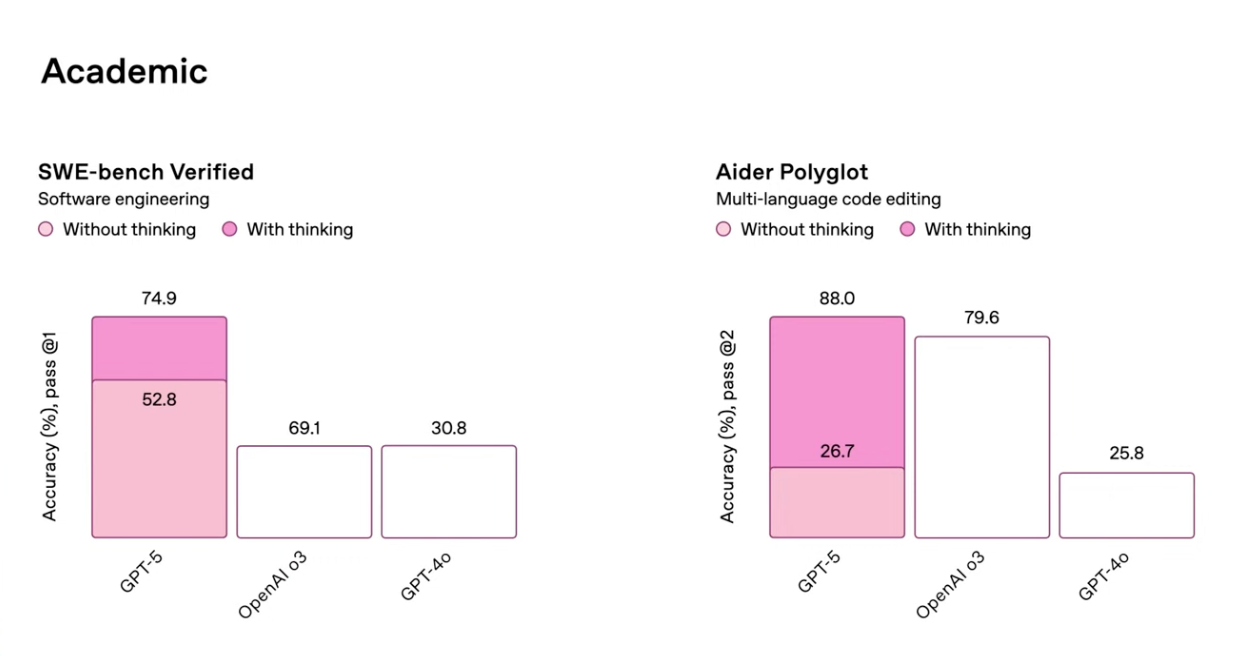
But for the developer community, the coding benchmarks immediately dominated the conversation. According to Cursor IDE’s detailed analysis, GPT-5 scored 74.9% on SWE-Bench Verified — a massive 20.3-point leap over GPT-4’s 54.6% and comfortably ahead of o3’s 69.1%. To put that in context, SWE-Bench Verified tests models on real software engineering tasks: resolving GitHub issues, fixing bugs, implementing features in actual codebases. A 20-point improvement in this benchmark isn’t just a number — it represents a fundamentally better ability to understand and modify existing code.
On the Aider Polyglot benchmark, which measures the ability to edit code across multiple programming languages, GPT-5 hit 88%. With Thinking mode enabled, that number climbs to an extraordinary 94%. The Aider benchmark is particularly relevant for professional developers because it tests the kind of cross-language context switching that real-world projects demand daily.
The language-specific accuracy numbers paint an equally striking picture. Python leads at 96%, followed by JavaScript/TypeScript at 94%, and Go/Rust at 92%. Multi-file refactoring — the kind of operation that touches multiple files in a coordinated way — jumped to 91%, up from GPT-4’s 67%. Test generation, an area where AI tools have historically struggled with edge cases, reached 93% compared to GPT-4’s 58%. According to Vellum AI’s comprehensive benchmark roundup, activating Thinking mode adds another +22.1 points on SWE-Bench and a staggering +61.3 points on Aider Polyglot. On the math front, AIME 2025 scores hit 94.6% without tools and a perfect 100% with Python tools. GPQA Diamond, which tests PhD-level scientific reasoning, landed at 85.7% without tools and 89.4% with tools.
The Independent Reality Check: 16x Engineer’s Uncomfortable Findings
The more impressive the marketing numbers, the more valuable independent evaluation becomes. And this is where the GPT-5 story gets genuinely interesting. 16x Engineer, an independent coding evaluation platform, ran GPT-5 through a battery of real-world coding tasks immediately after launch. Their methodology differs from SWE-Bench in a crucial way: they test the kinds of messy, ambiguous, context-dependent tasks that developers actually encounter daily, not the curated and well-defined problems that standard benchmarks favor.
The results were sobering. GPT-5’s average coding score: 7.46 out of 10. Claude Opus 4 scored 8.92. Claude Sonnet 4 scored 8.58. That’s not a close race — it’s a gap of nearly 1.5 points between GPT-5 and the top performer. In practical terms, that difference translates directly into more code review cycles, more debugging time, and lower first-attempt code quality.
The most shocking individual result was the TypeScript narrowing task. TypeScript’s type narrowing system is fundamental to modern web development — it’s how you safely handle union types, null checks, and discriminated unions. GPT-5 scored 1 out of 10 on this task. For context, the older GPT-4.1 scored 6 out of 10 on the exact same task. A newer, supposedly superior model performing five times worse on a core TypeScript capability is not just disappointing — it’s a regression that should concern any team heavily invested in TypeScript development.
To be fair, GPT-5 had genuine standout moments in the 16x evaluation. It scored 9.5 out of 10 on Next.js tasks, suggesting exceptional understanding of React’s server-side rendering framework. Benchmark visualization tasks earned 8.5 out of 10. But the overall verdict from the evaluation team was unambiguous: GPT-5 is “incremental, not revolutionary” — a direct contradiction of OpenAI’s launch messaging that positioned this as a generational leap in AI capability.
Task-by-Task Breakdown: Where GPT-5 Shines and Where It Stumbles
To get a fuller picture of GPT-5’s coding capabilities, we need to look beyond a single evaluation platform. Qodo’s PR Benchmark provides another valuable data point. They tested GPT-5 across 400 real-world pull requests sourced from over 100 open-source repositories. This isn’t synthetic data — these are actual code changes that real developers submitted and reviewed.
GPT-5 with medium-budget configuration scored 72.2 on the PR Benchmark, earning the top spot among all tested models. Its strengths were specific and measurable: broader bug detection that caught issues other models missed, precise code patches that required minimal human editing, and strong compliance with project-specific coding rules and conventions. For teams considering automated code review pipelines, these are exactly the capabilities that matter most.
However, the weaknesses were equally specific. False positive rates were higher than ideal — meaning GPT-5 flagged non-issues as problems, which can erode developer trust in automated review systems. Severity labeling was inconsistent, sometimes marking minor style issues as critical bugs and vice versa. For a production code review tool, this kind of inconsistency creates more work than it saves if not carefully calibrated.
Latent Space’s hands-on review provided perhaps the most provocative take, calling GPT-5 “the closest to AGI we’ve ever been.” Their standout example deserves detailed attention: GPT-5 successfully resolved a complex dependency conflict between Vercel AI SDK v5 and Zod 4 that both o3 and Claude Opus failed to handle. This type of intricate version-specific dependency resolution is a common pain point in real-world JavaScript development, and GPT-5’s ability to navigate it demonstrates genuine reasoning about package ecosystems that goes beyond pattern matching.
The Latent Space review also highlighted GPT-5’s ability to generate production-ready full-stack applications from single prompts. Combined with effective parallel tool calling as an agent, GPT-5 positions itself not just as a code generator but as a potential development partner. Final Round AI’s analysis reinforced this with data showing GPT-5 uses 45% fewer tool calls than o3 while achieving better results — a significant efficiency gain for agentic workflows where each tool call adds latency and cost.
But the same Latent Space review flagged an important trade-off. GPT-5’s writing quality is noticeably weaker than GPT-4.5, tending to produce what they characterized as “LinkedIn-slop” style content. This suggests OpenAI made deliberate optimization choices that favored reasoning and coding performance at the expense of natural language generation quality. If you use AI models for both coding and content creation, this trade-off is worth considering in your model selection strategy.
The Cursor Reality: Raw Developer Reactions From Day One
Perhaps the most telling indicator of GPT-5’s real-world coding performance came from developer Theo’s experience, which perfectly encapsulates the benchmark-versus-reality tension. Theo initially praised GPT-5’s capabilities based on early testing and benchmarks, then publicly walked it back after extended use in Cursor IDE, noting it was “nowhere near as good in Cursor” as the numbers suggested. This kind of real-time sentiment shift from an experienced developer is exactly why day-one benchmark announcements deserve healthy skepticism.
The gap between benchmark performance and IDE integration performance isn’t just about the model’s raw capabilities. It’s about how well the model handles the messy reality of development: incomplete context, ambiguous prompts, legacy code patterns, project-specific conventions, and the continuous back-and-forth that characterizes real coding sessions. Benchmarks test individual, isolated tasks. IDE integration tests sustained interaction quality over extended sessions.
Leon Furze published his comprehensive review the day after launch (August 8), describing GPT-5 as “a more streamlined o3” with notably less verbosity in its responses. He identified a significant performance tier between the free version and Pro with Thinking mode — a distinction that matters enormously for teams evaluating cost versus capability. He also noted that basic practical features like CSV export still fail, which raises questions about how well the model handles structured data operations despite its impressive benchmark scores. His bottom line resonated with the broader developer community: try it yourself before making judgments, and don’t let marketing hype drive your tooling decisions.
One area where GPT-5 demonstrated genuinely unprecedented performance deserves mention. On T2-bench’s telecom domain, it scored 96.7% where every other model tested sat below 49%. This kind of domain-specific dominance suggests that GPT-5’s training data or architecture gives it exceptional capabilities in certain specialized areas, even if its general-purpose coding falls short of the top competitors.
What This Means for Your Development Workflow
The most important lesson from GPT-5’s launch isn’t about any single benchmark score — it’s about the growing gap between curated benchmarks and real-world development experience. SWE-Bench 74.9% is undeniably impressive, and the 20-point improvement over GPT-4 represents genuine progress in AI-assisted software engineering. But 16x Engineer’s 7.46 out of 10 sends an equally clear message: GPT-5 isn’t ready to dethrone Claude Opus 4 as the most reliable coding assistant, at least not across the full spectrum of development tasks.
Here’s my practical guidance for developers evaluating GPT-5 starting today. First, leverage GPT-5 where it demonstrably excels — Next.js development, full-stack application generation from scratch, and complex dependency conflict resolution. These are areas where GPT-5 showed clear superiority even in independent testing. Second, for precision work like TypeScript type systems, discriminated unions, and type narrowing, Claude Opus 4 and Sonnet 4 remain more reliable choices based on current evidence. The TypeScript regression alone should give any TypeScript-heavy team pause before switching their primary coding assistant.
Third, the performance gap between standard and Thinking (Pro) mode is enormous — we’re talking +22 points on SWE-Bench and +61 on Aider. For any complex coding task, Thinking mode isn’t optional, it’s essential. Factor this into your cost calculations. Fourth, GPT-5’s true differentiator may be its agent capabilities rather than standalone code generation. The 45% reduction in tool calls compared to o3 combined with parallel execution makes it especially attractive for agentic development pipelines where efficiency compounds across multiple steps.
The AI coding tool landscape has evolved beyond simple benchmark competitions into the much more nuanced territory of “how reliably does this work in my specific codebase, with my specific tech stack, for my specific types of tasks?” GPT-5 is a genuine step forward for OpenAI, but calling it revolutionary would be premature based on the available evidence. The smartest approach right now isn’t picking a winner — it’s building a multi-model strategy that combines GPT-5, Claude Opus 4, and Claude Sonnet 4 based on the specific demands of each task. The developers who will benefit most from this new landscape aren’t the ones choosing sides; they’re the ones matching the right tool to each job.
Need help integrating AI coding tools into your workflow or building automation pipelines? Let’s find the right solution for your team.
Get weekly AI, music, and tech trends delivered to your inbox.



{kind=link}
{kind=link}
{kind=link}