
NVIDIA RTX 5090 Ti Rumors: Full GB202 Die, Up to 36GB GDDR7, and 600W+ TGP — Everything We Know
September 23, 2025
Circle of Fifths for Beat Making: 5 Chord Progression Tricks Every Producer Needs
September 24, 2025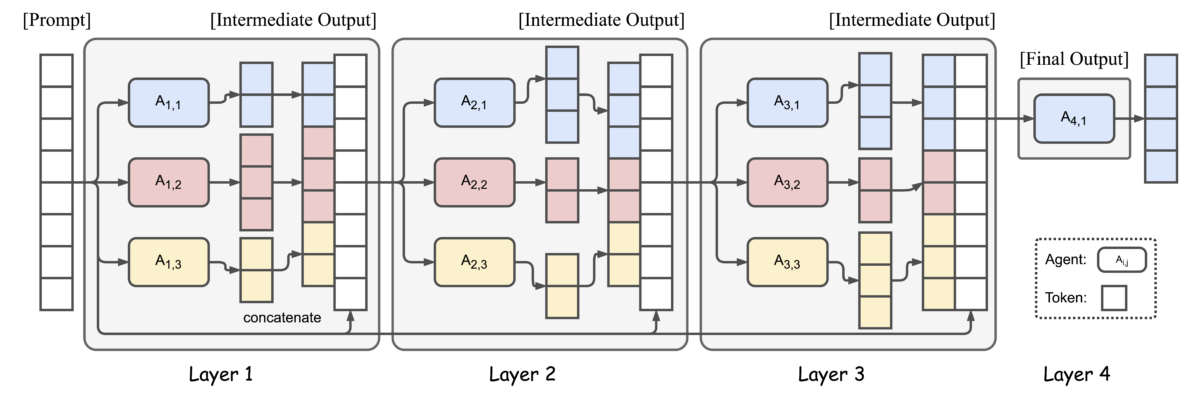
Six open-source models, combined in layers, just beat GPT-4o. AlpacaEval 2.0 score: 65.1% — outperforming GPT-4o’s 57.5% by a 7.6-point margin. That’s what Together AI’s Mixture of Agents (MoA) has proven. And in September 2025, Together AI doubled down by launching the GPU infrastructure to power it all at enterprise scale.
Together AI Mixture of Agents — A New Paradigm for Open-Source LLM Ensembles
The core idea behind MoA is deceptively simple: instead of relying on a single massive model, combine the strengths of multiple open-source models across layers. Together AI’s research team implemented this through a Proposer-Aggregator architecture.
Proposers generate diverse initial responses. WizardLM-2-8x22b, Qwen1.5-110B-Chat, Qwen1.5-72B-Chat, Llama-3-70B-Chat, Mixtral-8x22B-Instruct, and dbrx-instruct — six models answering the same prompt simultaneously. Because each model has different strengths, you naturally get a multi-perspective response pool.
The Aggregator takes all these responses and synthesizes them into a single, superior answer. In the default configuration, Qwen1.5-110B-Chat handles this role. The key insight: “every agent in the next layer uses all outputs from the previous layer as auxiliary information.”
Together AI Mixture of Agents Performance by the Numbers
- AlpacaEval 2.0: 65.1% (vs GPT-4o’s 57.5% — a +7.6pp gap)
- MT-Bench: 9.25±0.10 (vs GPT-4o’s 9.19)
- FLASK: Outperforms GPT-4o across correctness, factuality, and completeness
- Arena-Hard: State-of-the-art performance
What makes this remarkable is that every single model in the ensemble is fully open-source. Models that individually fall short of GPT-4o collectively surpass it through structural collaboration. Together AI’s researchers call this phenomenon “collaborativeness” in their foundational paper — individual models generate significantly better responses when given auxiliary outputs from other models, even less capable ones.
MoA API in Practice: Implementation Guide for Developers
Together AI didn’t leave MoA as a research paper. It’s available as a production API through the Chat Completions endpoint, with straightforward Python SDK integration.
from together import AsyncTogether, Together
async_client = AsyncTogether()
client = Together()
reference_models = [
"Qwen/Qwen3.5-397B-A17B",
"meta-llama/Llama-3.3-70B-Instruct-Turbo",
"deepseek-ai/DeepSeek-V3.1",
"mistralai/Mistral-Small-24B-Instruct-2501"
]
# Stage 1: Parallel proposer calls
results = await asyncio.gather(*[
async_client.chat.completions.create(
model=model, messages=messages,
temperature=0.7, max_tokens=512
) for model in reference_models
])
# Stage 2: Aggregator synthesis
aggregated = client.chat.completions.create(
model="Qwen/Qwen3.5-397B-A17B",
messages=[{"role": "user", "content": combined_prompt}],
stream=True
)You can configure anything from a basic 2-layer setup (4 Proposers → 1 Aggregator) to advanced 3+ layer configurations. The practical tip: use AsyncTogether for parallel proposer calls to minimize latency at the proposal stage.
MoAA: Distilling Ensemble Intelligence Into Smaller Models — ICML 2025
MoA’s limitation is obvious: running six models simultaneously is expensive. Together AI’s research team solved this with Mixture-of-Agents Alignment (MoAA), presented at ICML 2025. The core idea: distill MoA’s collective intelligence into a single, smaller model.
MoAA operates in two stages:
- MoAA-SFT: Fine-tune a smaller model on high-quality synthetic data generated by the MoA ensemble
- MoAA-DPO: Use MoA as a reward model for Direct Preference Optimization, further refining the smaller model
The results speak for themselves. Llama-3.1-8B jumped from 19.5 to 48.3 on Arena-Hard. Gemma-2-9B improved from 42 to 55.6. Small models with 8-9 billion parameters achieving performance comparable to models 10x their size. And generating synthetic data via MoA costs approximately 15% less than GPT-4o.
The most intriguing finding? Self-improvement loops are possible. When the strongest model in the MoA mix is trained on MoA-generated data, it still improves — enabling self-refining pipelines without relying on larger external models.
Instant Clusters GA: The GPU Infrastructure MoA Needed
On September 9, 2025, Together AI announced the general availability of Instant Clusters — self-service GPU infrastructure purpose-built for large-scale inference and distributed training like MoA.

GPU Options and Pricing
Support spans from NVIDIA Hopper to the latest Blackwell architecture:
- HGX H100 Inference: $1.76–$2.39/GPU-hr (based on commitment)
- HGX H100 SXM: $2.20–$2.99/GPU-hr
- HGX H200: $3.15–$3.79/GPU-hr
- HGX B200: $4.00–$5.50/GPU-hr
From single-node (8 GPUs) to hundreds of interconnected GPUs across multi-node clusters — provisioned in minutes via a single API call. What used to take days of procurement now takes minutes. NVIDIA Quantum-2 InfiniBand fabric, NVLink, and Kubernetes/Slurm orchestration come pre-configured.
Developer-Friendly Features
- Infrastructure-as-Code: Terraform and SkyPilot integration for code-managed clusters
- Episodic Training: Recreate clusters and remount original data/storage — ideal for intermittent workloads
- Independent Scaling: Scale compute and storage separately
- Burn-in Testing: NVLink/NVSwitch validation and NCCL all-reduce tests before deployment
Together AI’s Chief Scientist Tri Dao explained: “If we can spin up a clean NVIDIA Hopper or Blackwell GPU cluster with good networking in minutes, our researchers can spend more cycles on data, model architecture, system design, and kernels.”
September Platform Updates: 3,000x Batch API Expansion and New Models
Beyond Instant Clusters, September brought significant platform-wide improvements:
- Batch Inference API: Token queue limits jumped from 10M to 30B per model per user — a 3,000x increase. Cost? 50% of real-time API pricing
- New Models: Qwen3-Next-80B (thinking + instruction variants), Kimi-K2-Instruct-0905 (Moonshot’s 1T-parameter MoE model)
- Fine-Tuning Expansion: DeepSeek-V3.1, Qwen3-Coder-480B, and Meta Llama-4 variants now supported
- Sweden Data Center: Reduces RTT by 50–70ms for Northern/Central Europe, improving real-time app response times by 25–30%
- Evaluation Tools: LoRA and Dedicated Endpoints now supported for model evaluations
The 3,000x batch limit expansion is particularly significant for MoA workflows. Since MoA calls multiple models in parallel, batch processing at half the cost is a natural fit for synthetic data generation, offline evaluation, and high-accuracy content processing.
MoA vs Single Models: When Should You Use Each?
MoA isn’t a silver bullet. Time-to-first-token latency increases with each layer, making it unsuitable for real-time chat or streaming-first applications. Together AI acknowledges this and has flagged latency optimization as a priority.
Where MoA excels:
- Offline Batch Processing: Large-scale document analysis, synthetic data generation — where latency is secondary
- Accuracy-Critical Tasks: Legal document review, medical data analysis — where single-model limitations pose risk
- Model Distillation: Use MoA for maximum quality at research time, then deploy MoAA-distilled models in production
- Benchmarking/Evaluation: Use MoA as a judge for training data quality and model comparisons
For real-time chatbots, interactive coding assistants, and latency-sensitive services, single models or MoAA-distilled variants remain the better choice.
The Bigger Picture: Open-Source AI Infrastructure Comes of Age
Together AI’s September updates tell a story bigger than any single product launch. MoA proves that structural collaboration between open-source models can beat closed-source giants. Instant Clusters provides the production-grade GPU infrastructure to run it. And MoAA bridges the gap between ensemble quality and single-model deployment efficiency.
The pipeline is now complete: use MoA to find optimal responses, distill them into lightweight production models with MoAA, and provision on-demand training infrastructure through Instant Clusters. The “one giant model vs. open-source ensemble” debate is no longer a binary cost-performance tradeoff — it’s a full-stack strategy.
As more open-source models emerge, the MoA approach only gets stronger. September 2025 marks the moment Together AI assembled all the pieces. The question now isn’t whether open-source ensembles can compete — it’s how fast they’ll pull ahead.
Want to explore multi-agent AI systems like MoA or optimize your GPU infrastructure strategy? Let’s map out the right approach for your use case.
Get weekly AI, music, and tech trends delivered to your inbox.



{kind=link}
{kind=link}
{kind=link}