
Apple MacBook Pro M5 Pro vs M5 Max: Which Config Should You Choose?
October 31, 2025
Black Friday 2025 Plugin Deals: The Ultimate Buying Guide for Music Producers
November 3, 2025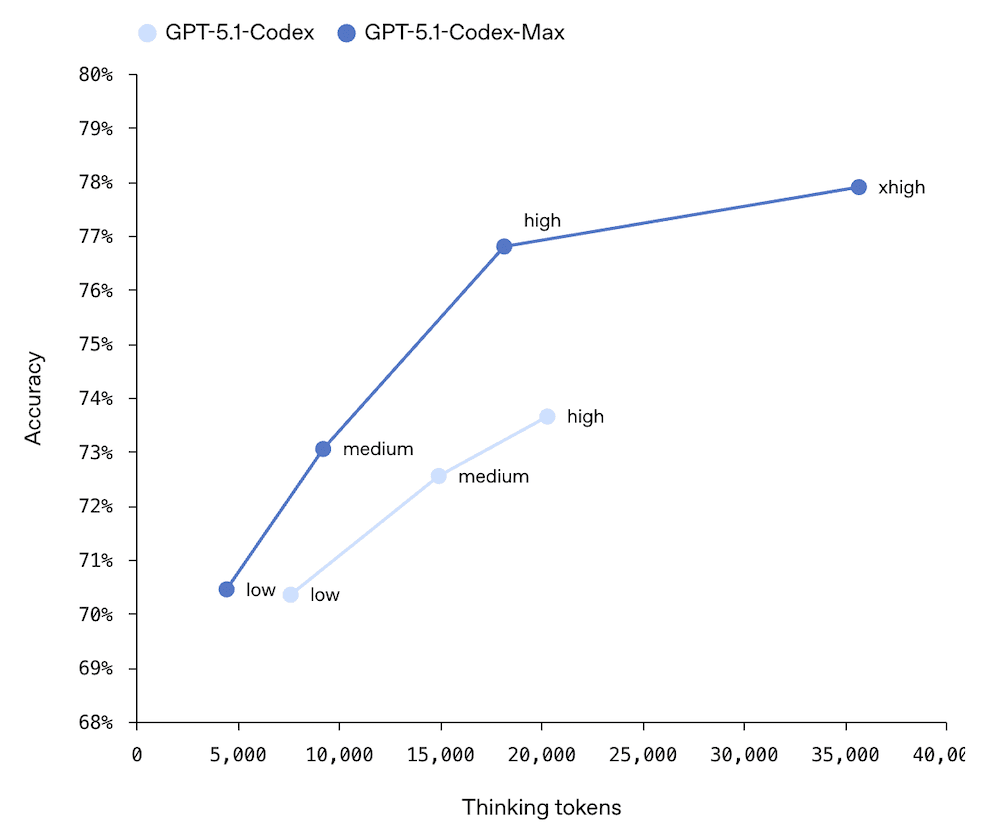
450 milliseconds. That’s the median API response time for GPT-5.1 — an 83% reduction from GPT-5. If you’re building production AI systems and that number doesn’t immediately grab your attention, let me put it another way: the workflow that used to take 30 seconds now finishes in under 5.
OpenAI officially launched GPT-5.1 on November 12, 2025, and this isn’t your typical incremental update. Three model variants, adaptive reasoning controls, 24-hour prompt caching, and built-in agentic tools — the GPT-5.1 launch signals a clear pivot from “smarter AI” to “AI you can actually deploy in production without losing sleep.”
With Black Friday season in full swing and development teams planning their 2026 AI infrastructure, the timing couldn’t be more strategic. I’ve been digging through the technical specs, running API tests, and analyzing the pricing — here’s everything that actually matters for developers and engineering leads.
Three Variants, Three Missions: Understanding the GPT-5.1 Launch Lineup
Unlike previous releases where you got one model and made it work for everything, the GPT-5.1 launch introduces three purpose-built variants — each optimized for a distinct production use case. This is a fundamental shift in how OpenAI thinks about model deployment.
GPT-5.1 Instant is the speed demon. Built for real-time applications like chatbots, customer support agents, and interactive tools, Instant uses adaptive reasoning to automatically calibrate how much compute it throws at each request. Simple classification? Minimal overhead. Nuanced analysis? It scales up. This auto-calibration happens per request, which means you’re not paying for deep reasoning when a quick answer will do. For teams running high-volume customer-facing applications, this alone could justify the migration from GPT-5.
GPT-5.1 Thinking is for when you need the model to genuinely reason through a problem. It supports reasoning effort levels from none all the way up to xhigh, making it ideal for complex research tasks, multi-step analysis, and scientific problem-solving. Think of it as the model you’d use for anything where getting the answer right matters more than getting it fast. The fact that it scored 94.0% on AIME 2025 — a mathematical olympiad benchmark — gives you a sense of the reasoning depth available at the xhigh level.
GPT-5.1 Codex-Max is arguably the most interesting variant for developers and engineering teams. It comes with two built-in tools — apply_patch for making file modifications and shell for executing commands directly. This isn’t just a coding assistant anymore; it’s an agentic coding partner that can modify codebases and run tests autonomously. Imagine pointing it at a GitHub issue, and having it read the codebase, write a patch, run the test suite, and submit a PR — all without human intervention. That’s the trajectory Codex-Max is on.
Perhaps the most overlooked feature is auto-routing between variants. You can let the API automatically direct requests to the optimal variant based on complexity, removing the operational burden of choosing the right model for each task. For teams running diverse workloads through a single API integration, this is a significant quality-of-life improvement that reduces the engineering overhead of model management.

The Latency Story: Why 83% Lower Response Time Changes Everything
Let’s talk numbers, because the latency improvements in the GPT-5.1 launch are genuinely transformative for production systems.
- p50 (median) latency: 450ms — down 83% from GPT-5
- p95 (tail) latency: 1.2 seconds — critical for SLA guarantees
- Speculative decoding: An additional 2x speedup on top of baseline improvements
Why does this matter beyond raw speed? In production, latency compounds. A chatbot that takes 3 seconds per response feels broken. An AI agent making 10 sequential tool calls at 3 seconds each means 30 seconds of waiting. Cut that to 450ms per call, and the same workflow completes in under 5 seconds. That’s the difference between a user who waits and a user who bounces.
The p95 number is equally important and often overlooked. In production, you don’t just care about the average case — you care about the worst case. A p95 of 1.2 seconds means that 95% of all requests complete within 1.2 seconds. For teams writing SLA guarantees into their contracts, this is the number that determines whether you can promise a 2-second response time to your customers.
Real-world validation is already coming in. Sierra, an AI customer experience platform, reported a 20% improvement in low-latency tool calling after switching to GPT-5.1. For companies running AI-powered customer support at scale, that translates directly to better resolution times, lower compute costs, and reduced customer churn. When your AI agent resolves issues faster, customers are happier and your infrastructure costs drop simultaneously.
The speculative decoding improvement deserves its own mention. This technique generates multiple candidate tokens in parallel and verifies them, effectively doubling throughput without sacrificing accuracy. Combined with the baseline 83% latency reduction, you’re looking at response times that were unthinkable for frontier models just six months ago.
Adaptive Reasoning and 24-Hour Prompt Caching: The Cost Optimization Duo
Two features in the GPT-5.1 launch stand out as production game-changers that don’t get enough attention in the headlines. Both directly impact your monthly AI infrastructure bill.
Adaptive reasoning_effort Parameter
GPT-5.1 introduces a reasoning_effort parameter with five levels: none, low, medium, high, and xhigh. This gives developers unprecedented control over the cost-performance tradeoff on a per-request basis.
Consider a typical production pipeline for a customer support application:
- Spam/intent classification — reasoning_effort: none or low. Fast, cheap, high volume.
- Standard FAQ responses — reasoning_effort: medium. Good balance of quality and cost.
- Complex technical troubleshooting — reasoning_effort: high. Detailed, accurate analysis needed.
- Legal/compliance-sensitive responses — reasoning_effort: xhigh. Maximum accuracy, no shortcuts.
Previously, you’d run everything through the same model at the same cost. Now, you can route each request to the appropriate reasoning level, potentially cutting costs by 40-60% on high-volume workloads while maintaining quality where it matters. The key insight is that most production traffic is simple — it’s the long tail of complex requests that needs the heavy compute. By right-sizing reasoning per request, you stop overpaying for the 80% of requests that don’t need deep thinking.
24-Hour Extended Prompt Caching
This is where the math gets really interesting. GPT-5.1’s extended prompt caching keeps your system prompts and repeated context in cache for a full 24 hours — up from the previous shorter cache windows. The pricing difference is dramatic:
- Uncached input tokens: $1.25 per million
- Cached input tokens: $0.125 per million — a 90% cost reduction
Let me run through a concrete scenario. Say you’re running a production application that handles 100,000 API calls per day, each with a 2,000-token system prompt. Without caching, the system prompt tokens alone cost you $250 per day (200M tokens x $1.25/M). With 24-hour caching and a high cache hit rate, that drops to roughly $25 per day. Over a month, that’s approximately $6,750 in savings on just the system prompt portion of your costs.
The practical implication: standardize your system prompts across similar request types. The more consistent your prompts are, the higher your cache hit rate, and the more you save. It’s the simplest ROI optimization available in the GPT-5.1 ecosystem, and it requires zero changes to your application logic — just prompt architecture discipline.
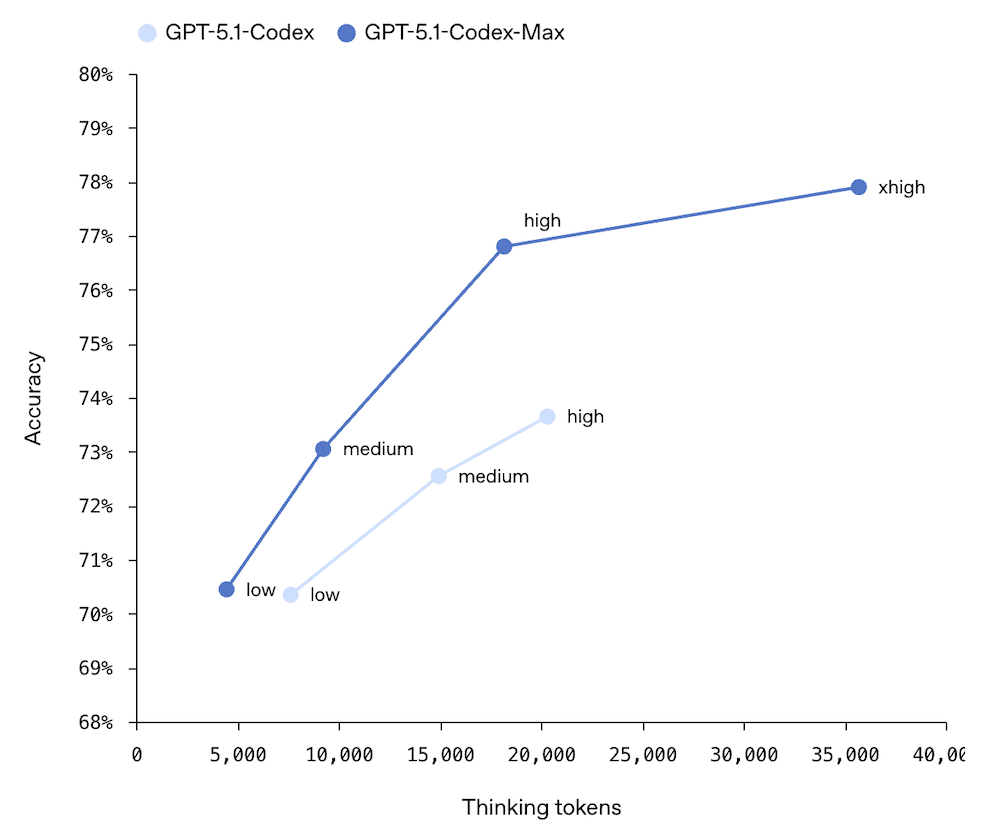
Benchmarks and Context Window: Incremental Gains, but the Right Ones
Let’s be honest — the benchmark improvements from GPT-5 to GPT-5.1 are evolutionary, not revolutionary. But the specific areas where improvements landed tell a clear story about OpenAI’s priorities.
- SWE-bench: 76.3% (up from GPT-5’s 72.8%) — a 3.5 percentage point improvement in real-world software engineering tasks
- GPQA Diamond: 88.1% — graduate-level science question accuracy
- AIME 2025: 94.0% — mathematical olympiad-level problem solving
The SWE-bench improvement is particularly meaningful because it measures the model’s ability to resolve actual GitHub issues — not synthetic coding challenges, but real-world bugs and feature requests from open-source projects. This is exactly the kind of work Codex-Max was specifically designed for. Combined with the apply_patch and shell tools, GPT-5.1 is positioning itself not just as a code generator, but as a genuine development agent that can participate in your engineering workflow.
The context window has been expanded to 400K tokens with a maximum output of 128K tokens. To put that in perspective, 400K tokens is roughly equivalent to a 300-page technical book. You can feed entire codebases, documentation sets, or long conversation histories into a single request. For long-running agentic tasks, a new compaction feature automatically summarizes older context to keep the model operating efficiently within its window — addressing one of the biggest pain points in extended AI agent sessions where context would previously overflow and degrade quality.
OpenAI has also added response styles customization, allowing you to control the model’s output tone and format more precisely. This is particularly useful for teams generating content across multiple channels — the same model can write formal technical documentation and conversational marketing copy, with the style controlled via API parameters rather than prompt engineering gymnastics.
Pricing Breakdown and Developer Strategy for 2026
Here’s the straightforward pricing for the GPT-5.1 API:
- Input tokens: $1.25 per million ($0.125 per million when cached)
- Output tokens: $10 per million
With Black Friday deals on cloud credits and the typical end-of-year infrastructure planning cycle, now is the ideal time for development teams to evaluate GPT-5.1 for their 2026 stack. Here’s a practical, step-by-step strategy for making the evaluation productive:
- Run A/B latency tests on real workloads: Compare GPT-5 vs GPT-5.1 on your actual production traffic, not synthetic benchmarks. The 83% improvement is impressive on paper, but real-world gains depend on your specific use case, request complexity, and output length patterns.
- Build a reasoning_effort optimization map: Categorize every API call type in your system by complexity. Assign appropriate reasoning levels (start with medium as your default) and measure quality metrics at each level. You’ll likely find that 60-70% of your traffic can run at low or medium without any quality degradation.
- Redesign your prompt architecture for caching: Maximize your 24-hour cache hit rate by using consistent, modular system prompts. Move variable content to user messages and keep system prompts stable across request types. This is free money on the table — literally a prompt refactoring exercise that pays for itself in days.
- Prototype agentic workflows with Codex-Max: If you have CI/CD pipelines, automated testing, or code review processes, build a proof of concept using apply_patch and shell. Start small — maybe automated bug triage or test generation — and expand from there.
- Run an auto-routing experiment: Let OpenAI’s auto-routing handle model selection for one week of production traffic. Compare the costs, latency distribution, and quality scores against your manual routing strategy. You might be surprised at how well the auto-router performs.
The GPT-5.1 launch isn’t about a dramatic leap in intelligence — it’s about making AI genuinely production-ready at scale. Lower latency, granular cost controls, extended caching, and agentic tools address the exact pain points that have kept engineering teams from fully committing to LLM-powered production systems. For anyone planning their 2026 AI infrastructure, this release fundamentally shifts the conversation from “can we use AI in production” to “how do we optimize our AI production stack for maximum efficiency and reliability.”
Need help integrating GPT-5.1 into your production pipeline, or building AI-powered automation from scratch? Let’s talk.
Get weekly AI, music, and tech trends delivered to your inbox.



{kind=link}
{kind=link}
{kind=link}