
NAMM 2026 오디오 인터페이스 프리뷰: $500 이하 최고의 신제품 5선
1월 8, 2026
NAMM 2026 기타 베이스 프리뷰: Fender, Gibson, PRS 신제품 7가지 핵심 정리
1월 9, 2026
2024년 12월 20일, OpenAI o3가 발표되었을 때 ARC-AGI 벤치마크에서 87.5%라는 점수가 화면에 떴습니다. 이전 최고 기록이 55.5%였다는 걸 생각하면, 이건 단순한 개선이 아니라 완전한 차원 이동이었습니다. 그리고 지금, 1년이 지난 2026년 1월—OpenAI o3가 실제로 AI 추론의 판도를 바꿔놓았는지 냉정하게 돌아볼 시점입니다.
OpenAI o3는 어떻게 ARC-AGI를 박살냈는가
ARC-AGI는 인간이 직관적으로 풀 수 있지만 기존 AI 모델에게는 극도로 어려운 추상 추론 문제를 다루는 벤치마크입니다. GPT-4가 5% 미만, o1이 25% 수준에 머물렀던 이 시험에서 o3는 저연산 모드에서도 75.7%를, 고연산 모드에서는 87.5%를 기록했습니다. ARC Prize 재단의 분석에 따르면, 이는 “딥러닝 기반 프로그램 탐색(deep learning-guided program search)”이라는 근본적으로 새로운 접근 방식 덕분이었습니다.
핵심은 o3가 단순히 패턴을 매칭하는 것이 아니라, 자연어 기반의 사고 연쇄(Chain of Thought)를 통해 프로그램을 생성하고 탐색한다는 점입니다. 마치 프로그래머가 문제를 분석하고, 가설을 세우고, 코드를 작성해 검증하는 과정을 모델 내부에서 수행하는 것과 같습니다. 다만 고연산 모드의 비용이 작업당 $4,560에 달한다는 점은 현실적 한계로 지적되었습니다.
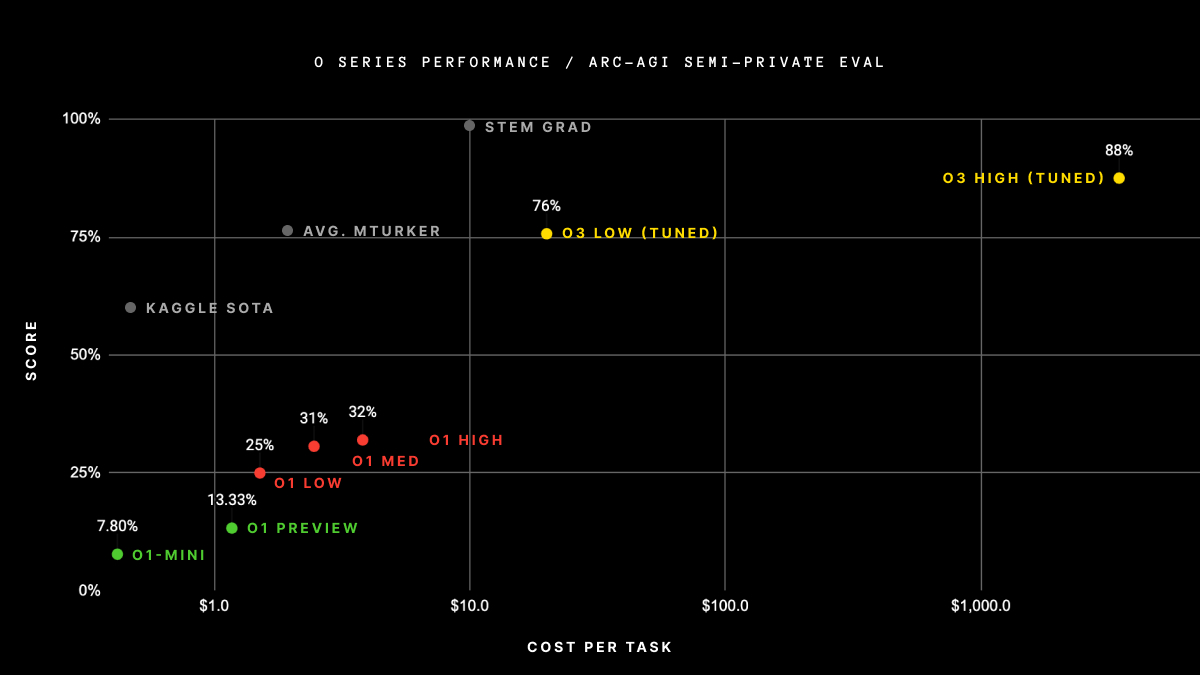
벤치마크로 보는 o3의 압도적 성능
Helicone의 상세 비교 분석에 따르면, OpenAI o3는 o1 대비 거의 모든 영역에서 극적인 성능 향상을 보여주었습니다. 수치로 직접 확인해 보겠습니다.
- AIME (수학 경시대회): 96.7% — o1의 83.3% 대비 13.4%p 상승
- Codeforces (프로그래밍): Elo 2727 — o1의 1891에서 836점 점프, 상위 175위 수준
- EpochAI Frontier Math: 25.2% — 다른 모든 모델이 2% 미만인 영역에서 혼자 25% 돌파
- GPQA Diamond (대학원 과학): 87.7% — 박사급 화학·물리·생물 문제를 87% 정답
- SWE-bench (소프트웨어 엔지니어링): 71.7% — 실제 GitHub 이슈 해결 능력
특히 Frontier Math 결과는 충격적이었습니다. 이 벤치마크는 현역 수학자들이 풀기 어려운 문제들로 구성되어 있는데, 기존 모델들이 모두 2% 미만의 정답률을 기록한 반면 o3는 단독으로 25.2%를 달성했습니다. 이는 단순한 성능 향상이 아니라, AI 추론 능력의 질적 변화를 보여주는 지표였습니다.
o3-mini에서 o3 풀 버전까지: 출시 타임라인
2024년 12월 20일의 발표 이후, OpenAI는 단계적 출시 전략을 취했습니다. 2025년 1월 31일에 먼저 o3-mini가 공개되었고, o3 풀 버전은 2025년 4월 16일에 정식 출시되었습니다.
o3-mini는 가성비에 초점을 맞춘 모델이었습니다. 입력 100만 토큰당 $1.10, 출력 100만 토큰당 $4.40의 가격으로, o1-mini 대비 63% 저렴하면서도 24% 빠르고, 심각한 실수는 39% 줄었습니다. 추론 노력(reasoning effort)을 low, medium, high 세 단계로 조절할 수 있어서, 간단한 질문에는 빠르고 저렴하게, 복잡한 문제에는 깊이 있게 대응할 수 있는 유연성을 제공했습니다.
4월에 출시된 o3 풀 버전은 코딩, 수학, 과학, 시각 인식 전 분야에서 최첨단 성능을 기록하며, ChatGPT의 모든 도구를 에이전틱하게 활용할 수 있는 최초의 추론 모델이 되었습니다. Codeforces, SWE-bench, MMMU 등에서 SOTA(State of the Art)를 달성하며 발표 당시의 벤치마크 약속을 실제로 이행했습니다.
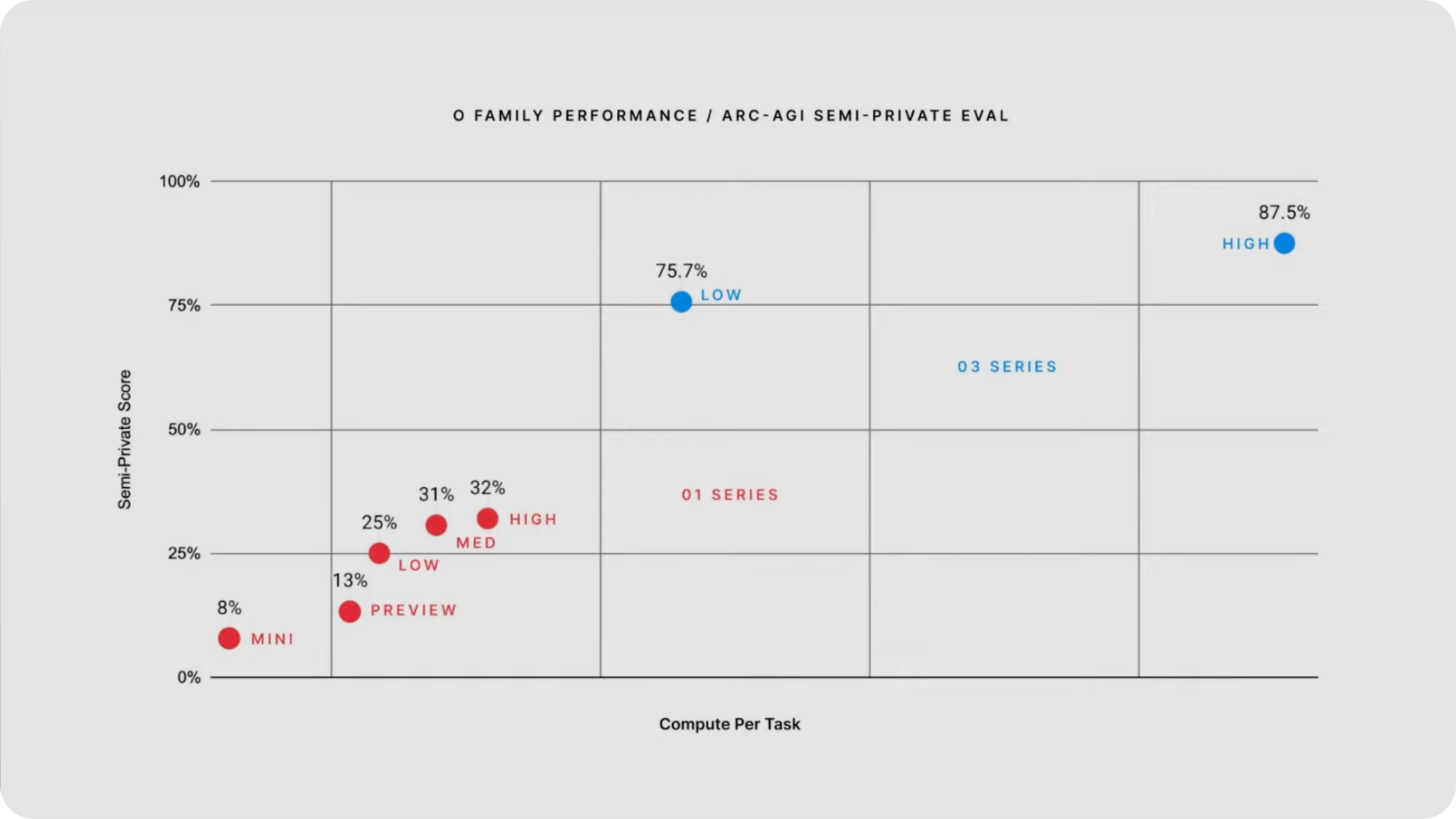
심의적 정렬(Deliberative Alignment): o3의 숨겨진 혁신
벤치마크 점수 뒤에 숨어 있지만 어쩌면 더 중요한 혁신은 “심의적 정렬(deliberative alignment)”입니다. Adaline Labs의 기술 분석에 따르면, o3는 각 프롬프트를 실시간으로 평가하여 안전성 정책을 사고 과정에 통합합니다.
기존 모델들은 학습 시점에 안전성 가드레일을 구워 넣었습니다. 하지만 o3는 추론 과정 자체에서 “이 요청이 안전 정책에 부합하는가?”를 능동적으로 판단합니다. 이는 추론 능력이 강해질수록 더 정교한 안전 장치가 필요하다는 인식에서 나온 설계입니다. 단순히 더 똑똑한 모델이 아니라, 더 책임감 있게 똑똑한 모델을 만들겠다는 방향성이 인상적입니다.
또한 o3의 핵심 기술인 테스트 타임 서치(test-time search)는 추론 스케일링의 새 패러다임을 열었습니다. 학습 단계에서 더 많은 데이터를 넣는 대신, 추론 단계에서 여러 후보 사고 경로를 생성하고 최적의 답을 선택하는 방식입니다. 이 접근법은 DeepSeek R1 등 다른 추론 모델에도 영향을 미치며, 2025년 AI 업계의 핵심 트렌드로 자리 잡았습니다.
1년이 지난 지금, o3가 남긴 것
OpenAI o3 발표 이후 1년이 지난 2026년 1월, 돌아보면 o3는 세 가지 측면에서 AI 추론의 판도를 확실히 바꿔놓았습니다.
첫째, 추론 스케일링이 새로운 성능 향상 축이 되었습니다. 학습 데이터 확대와 모델 크기 증가에 의존하던 기존 패러다임에서, 추론 시점의 연산량 조절이라는 새로운 차원이 추가되었습니다. 같은 모델이라도 문제의 난이도에 따라 생각하는 시간을 조절할 수 있다는 개념은 AI 활용 방식 자체를 바꿔놓았습니다.
둘째, 경쟁 구도가 완전히 재편되었습니다. Google의 Gemini, Anthropic의 Claude, 그리고 오픈소스 진영의 DeepSeek까지—모든 주요 플레이어가 추론 모델 개발에 뛰어들었습니다. o3가 증명한 “생각하는 AI”의 가능성이 전체 산업의 연구 방향을 바꿔버린 셈입니다.
셋째, ARC-AGI-2라는 더 어려운 도전이 시작되었습니다. ARC Prize 재단은 o3의 돌파를 인정하면서도 “아직 쉬운 문제도 틀린다”는 한계를 지적하며 더 높은 난이도의 벤치마크를 예고했습니다. AI 추론 연구의 다음 목표가 명확해진 것입니다.
결국 o3의 가장 큰 유산은 특정 벤치마크 점수가 아니라, AI가 “패턴을 외우는 기계”에서 “생각하는 시스템”으로 진화할 수 있다는 것을 실증한 데 있습니다. 2026년 CES에서 쏟아지는 AI 제품들의 근간에도 이 추론 능력의 진보가 깔려 있습니다. AI 기술을 비즈니스에 도입하려는 기업이라면, 단순한 자동화를 넘어 추론 기반 시스템 설계를 고려해야 할 시점입니다.
AI 추론 모델 도입, 자동화 파이프라인 구축, 기술 컨설팅이 필요하시다면 편하게 연락해 주세요.
매주 AI, 음악, 테크 트렌드를 이메일로 받아보세요.



{kind=link}
{kind=link}
{kind=link}