
음악 산업 매출 2025 분석: 스트리밍 반기 56억 달러 신기록, 바이닐 10억 달러 돌파 임박
12월 10, 2025
음악 프로젝트 아카이빙 완벽 가이드: 연말 정리를 위한 5단계 백업 전략
12월 11, 2025
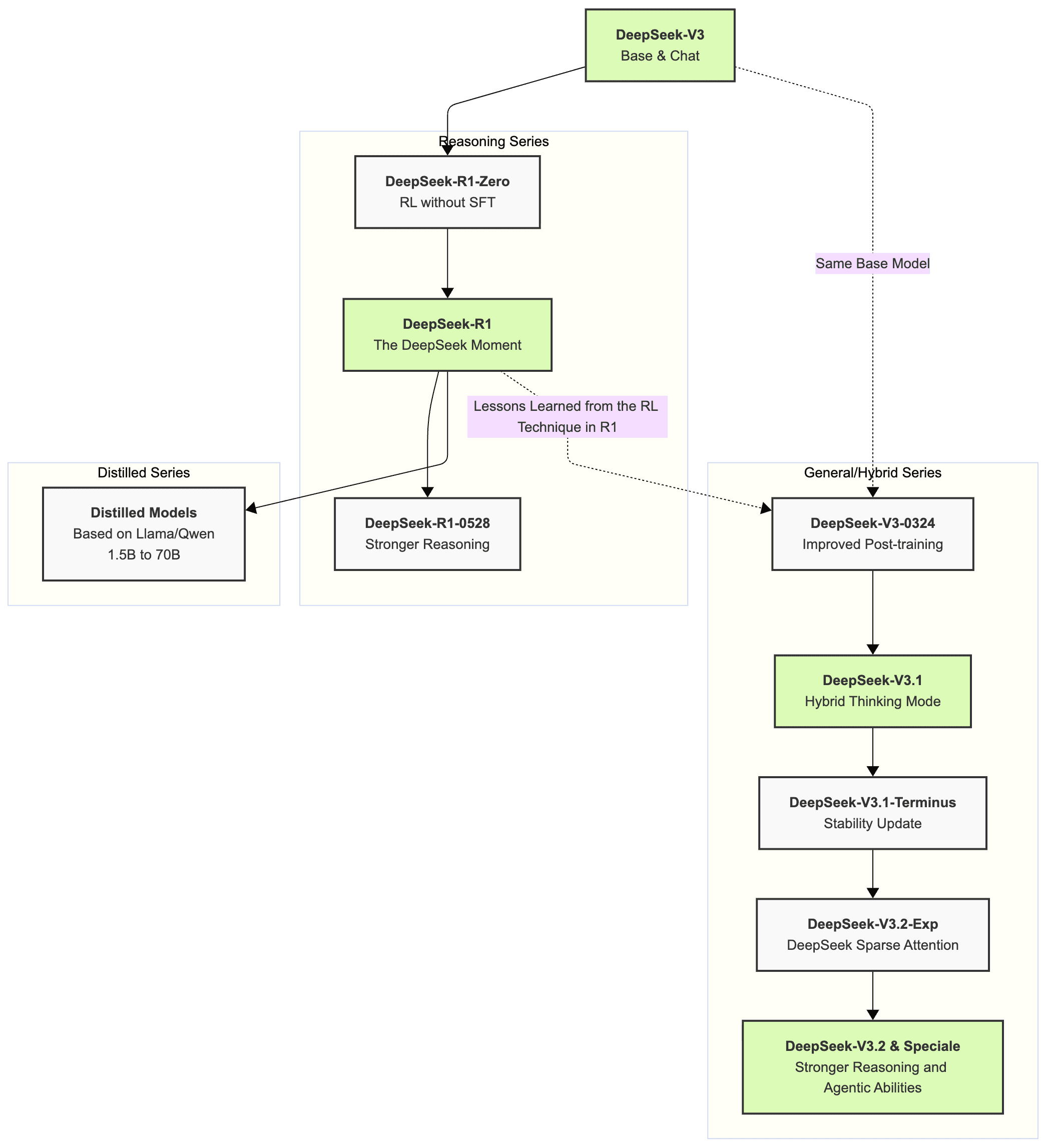
560만 달러. OpenAI가 연간 50억 달러를 태우는 동안, 200명짜리 중국 AI 연구소 하나가 이 금액으로 업계 판도를 완전히 뒤집었습니다. 2025년은 DeepSeek의 해였습니다. DeepSeek 2025 연간 리뷰를 통해, 이 작은 연구소가 어떻게 실리콘밸리의 거인들을 긴장시켰는지 되짚어 봅니다.
DeepSeek는 어디서 왔는가: 헤지펀드에서 AI 혁명으로
DeepSeek AI는 2023년 중국의 퀀트 헤지펀드 High-Flyer의 창립자 량원펑(Liang Wenfeng)이 설립한 AI 연구소입니다. 직원 수 약 200명. OpenAI의 3,500명과 비교하면 약 17분의 1 규모입니다. 그런데 이 작은 팀이 2025년 내내 글로벌 AI 업계를 뒤흔들었습니다.
비결은 효율성이었습니다. NVIDIA H800 GPU 2,048장으로 V3 사전학습에 278만 8천 GPU 시간을 투입했고, 학습 비용은 560만 달러에 불과했습니다. 같은 수준의 성능을 내기 위해 OpenAI가 쓴 비용의 수백 분의 1입니다. MIT Technology Review는 DeepSeek가 AI의 기존 플레이북을 완전히 찢어버렸다고 평가했습니다. 더 놀라운 것은 이 효율성이 단순히 하드웨어 최적화가 아닌, 근본적으로 새로운 학습 알고리즘과 아키텍처 설계에서 비롯되었다는 점입니다.
2025년 타임라인: 분기별 충격파
1월: R1 출시와 월스트리트 패닉
2025년 1월, DeepSeek-R1이 공개되었습니다. OpenAI의 o1과 동등한 추론 성능을 보여주면서, ‘저비용 AI 학습’이라는 개념이 현실로 증명된 순간이었습니다. 핵심 기술은 GRPO(Group Relative Policy Optimization)로, 별도의 보상 모델 없이도 강화학습이 가능한 혁신적 기법이었습니다. 기존 RLHF 방식은 보상 모델을 별도로 학습시켜야 했기 때문에 비용과 복잡성이 두 배로 늘어났는데, GRPO는 이 과정을 완전히 제거한 것입니다.
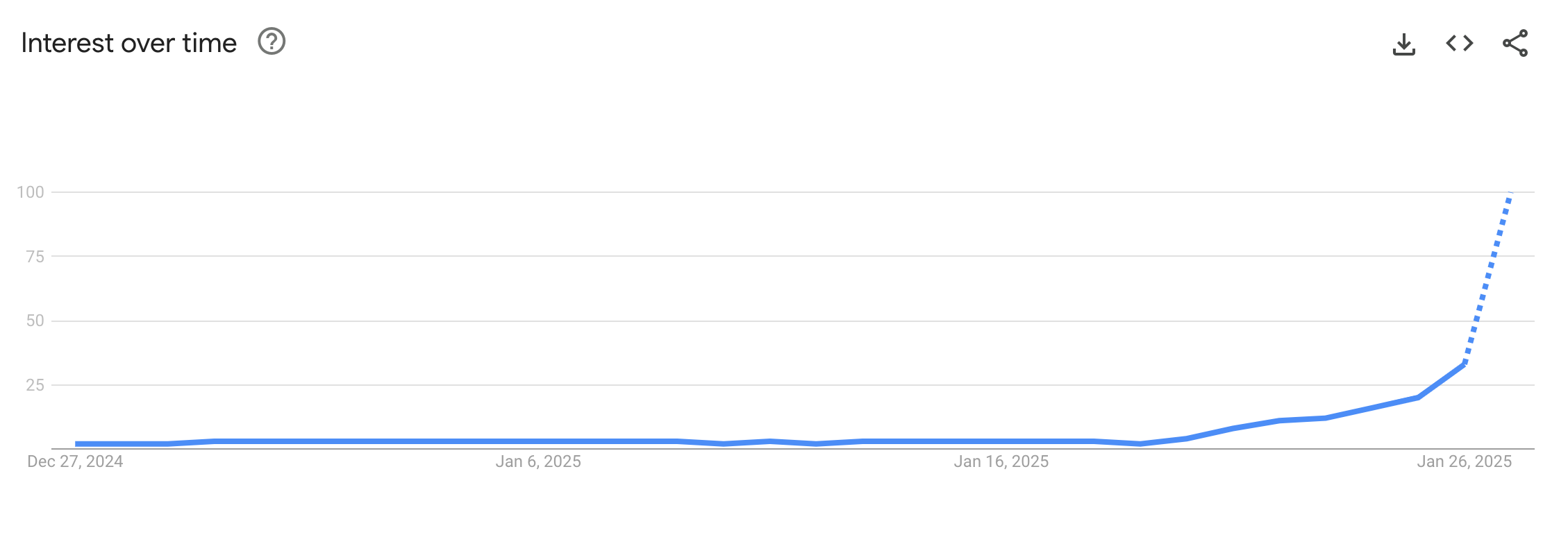
1월 27일, 금융시장이 반응했습니다. 엔비디아 주가가 하루 만에 6,000억 달러 폭락 — 미국 역사상 단일 종목 최대 시가총액 손실이었습니다. 같은 날 DeepSeek 앱은 Apple App Store에서 ChatGPT를 제치고 1위에 올랐습니다. “거대한 GPU 인프라만이 AI의 미래”라는 월스트리트의 테제가 흔들린 겁니다. 투자자들의 질문은 단순했습니다: “560만 달러면 충분한데, 왜 수백억 달러를 GPU에 투자해야 하지?”
3월: V3-0324, GPT-4.5를 넘다
3월에 출시된 DeepSeek-V3-0324는 R1의 강화학습 기법을 기본 모델 아키텍처에 통합해 추론 능력을 한 단계 끌어올렸습니다. GPT-4.5를 여러 벤치마크에서 능가하면서, “오픈소스 AI가 클로즈드 모델을 따라잡는 것은 시간문제”라는 주장이 더 이상 과장이 아니게 되었습니다. 특히 코딩과 수학 관련 벤치마크에서의 성능 향상이 두드러졌으며, 이는 R1에서 학습된 체계적 추론 능력이 범용 모델에도 성공적으로 전이될 수 있다는 것을 보여준 중요한 사례였습니다.
5월: R1-0528, 환각 45% 감소
5월의 R1-0528 업데이트는 추론 토큰을 23K까지 두 배로 늘리면서 동시에 환각(hallucination)을 45~50% 줄였습니다. AI 모델의 가장 큰 약점 중 하나를 정면으로 공략한 것입니다. 단순히 더 똑똑해진 게 아니라, 더 신뢰할 수 있게 된 겁니다. 실무에서 AI를 도입하려는 기업들에게 이 환각 감소율은 벤치마크 점수보다 더 중요한 지표였습니다.
8월: V3.1, Mixture of Experts의 정수
8월에 출시된 DeepSeek-V3.1은 671B 파라미터 중 37B만 활성화하는 MoE(Mixture of Experts) 아키텍처의 정수를 보여줬습니다. 하이브리드 사고 모드를 지원하고, 128K 컨텍스트 윈도우를 탑재했습니다. 거대한 모델이지만 실행 비용은 작은 모델 수준인, DeepSeek만의 효율성 철학이 고스란히 반영된 결과입니다. 또한 DeepSeek Sparse Attention 메커니즘을 도입해 긴 컨텍스트에서의 처리 효율성을 크게 개선했습니다. 이는 실무에서 긴 문서를 처리하거나 복잡한 코드베이스를 분석할 때 직접적으로 체감되는 차이였습니다.
12월: V3.2, 구글과 OpenAI에 정면 도전
불과 10일 전인 12월 1일, DeepSeek-V3.2와 V3.2-Speciale가 공개되었습니다. Bloomberg은 이 모델들이 구글과 OpenAI의 최신 모델과 정면으로 경쟁한다고 보도했습니다. 2025년을 시작할 때 “신흥 도전자”였던 DeepSeek가, 연말에는 “주요 경쟁자”로 자리매김한 것입니다. 1년 만에 6개의 주요 모델을 출시하면서 한 번도 품질을 타협하지 않은 점이 놀랍습니다.
DeepSeek 2025 연간 리뷰: 업계의 반응과 파급 효과
DeepSeek의 영향력은 단순히 “좋은 모델 하나 더”가 아닙니다. 업계 전체의 전략을 바꿨습니다.
- 구글: DeepSeek에 대응하기 위해 Gemini 2.0 Flash를 서둘러 출시했습니다. 기존 출시 일정을 앞당긴 것으로 알려졌습니다.
- OpenAI: 무료 o3-mini 모델을 공개했고, 샘 알트만은 R1을 “인상적”이라고 평가했습니다. 오픈소스 진영의 압박이 가격 정책에 직접적 영향을 준 첫 사례입니다.
- 엔비디아: 하루 6,000억 달러 시총 증발 후 GPU 수요 테제에 대한 근본적 의문이 제기되었습니다. AI 학습이 더 적은 GPU로 가능하다면, 엔비디아의 성장 전망도 재평가가 필요합니다.
- 벤치마크 비용 혁명: 동일 수준의 AI 벤치마크 점수를 달성하는 비용이 2025년 한 해 동안 태스크당 4,500달러에서 11.64달러로 급락했습니다. 약 387배의 비용 효율화입니다.
Brookings Institution은 DeepSeek가 빅테크 독점보다 경쟁이 더 나은 결과를 만든다는 것을 증명했다고 분석했습니다. 오픈소스 접근법이 폐쇄형 모델 패러다임을 정면으로 흔든 것입니다. SEO.ai의 통계 분석에 따르면, DeepSeek는 출시 직후 전 세계 AI 관련 검색량에서 ChatGPT에 이어 2위를 기록하기도 했습니다.
DeepSeek의 4가지 핵심 기술 혁신
DeepSeek가 단순히 “저렴한 AI”가 아닌 이유는 기술적 혁신의 깊이에 있습니다. 2025년 동안 이 연구소가 선보인 네 가지 핵심 기술을 살펴봅니다.
- GRPO (Group Relative Policy Optimization): 별도 보상 모델 없이 강화학습을 가능하게 한 기법. 학습 파이프라인의 복잡성과 비용을 동시에 줄였습니다.
- MoE (Mixture of Experts) 아키텍처: 671B 전체 파라미터 중 37B만 활성화하여 거대 모델의 지식은 유지하면서 실행 비용은 소형 모델 수준으로 낮췄습니다.
- DeepSeek Sparse Attention: 긴 컨텍스트(128K 토큰)에서의 연산 효율성을 획기적으로 개선한 어텐션 메커니즘입니다.
- 완전 오픈소스: 코드, 가중치, 기술 논문 모두 공개. 이는 전 세계 연구자들의 기여를 이끌어내는 동시에, 폐쇄형 모델 기업들에 가격 인하 압박을 가했습니다.
4가지 핵심 교훈: 2025년이 AI 업계에 남긴 것
첫째, 돈이 전부가 아닙니다. 560만 달러 vs 50억 달러. DeepSeek는 제한된 자원으로 더 창의적인 방법을 찾았고, 그 결과물은 수십억 달러를 태운 경쟁자들과 동등하거나 더 나았습니다. 이는 AI뿐 아니라 모든 기술 분야에 적용되는 교훈입니다.
둘째, 오픈소스가 경쟁 우위입니다. 코드, 가중치, 논문 — DeepSeek는 모든 것을 공개했습니다. 이 전략은 전 세계 연구자들의 기여를 이끌어냈고, 폐쇄형 모델 기업들에게는 가격 인하와 무료 모델 출시라는 압박을 가했습니다.
셋째, MoE 아키텍처가 미래입니다. 671B 파라미터 중 37B만 활성화하는 방식은 성능과 효율성 사이의 오래된 트레이드오프를 해결했습니다. 이 접근법은 이제 업계 표준으로 자리잡고 있습니다.
넷째, API 가격 경쟁은 시작됐을 뿐입니다. DeepSeek의 API 가격은 백만 토큰당 입력 $0.55/출력 $2.19입니다. OpenAI o1의 $15/$60과 비교하면 약 30분의 1. 이 가격 압박은 2026년에도 계속될 것이며, AI를 활용하는 기업과 개발자 모두에게 혜택이 돌아갈 것입니다.
2026년 전망: DeepSeek는 어디로 가는가
2025년을 마무리하며, DeepSeek의 궤적은 분명합니다. V3.2-Speciale이 보여준 성능은 2026년에 이 연구소가 OpenAI, Google, Anthropic과 본격적으로 최상위 경쟁을 벌일 것임을 시사합니다. 수학 영역에서 DeepSeekMath-V2가 퍼트넘 경시대회에서 120점 만점에 118점을 기록한 것(인간 최고 점수: 90점)은 특정 도메인에서의 초인적 성능이 이미 실현되고 있음을 보여줍니다.
AI 업계의 2025년은 “큰 자본 = 더 나은 AI”라는 공식이 깨진 해로 기록될 것입니다. DeepSeek는 그 균열의 중심에 서 있었습니다. 2026년, 이 균열이 어떤 새로운 지형을 만들어낼지 — 그것이 지금 가장 흥미로운 질문입니다.
AI 산업 트렌드 분석이나 기술 자동화 시스템 구축에 관심이 있으시다면, Sean Kim에게 문의해 보세요.
매주 AI, 음악, 테크 트렌드를 이메일로 받아보세요.



{kind=link}
{kind=link}
{kind=link}